
2024 Q4 PaddleMIX(五)热身任务——Stable Diffusion
本文最后更新于 2024-11-12,文章内容可能已经过时。
PaddleMIX/ppdiffusers/examples/stable_diffusion/README.md at develop · PaddlePaddle/PaddleMIX
本文对于PaddleMIX Stable Diffusion训练推理流程重新进行梳理。
实验环境:aistudio v100 32G
模型介绍
Stable Diffusion 是一个基于 Latent Diffusion Models(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。具体来说,得益于 Stability AI 的计算资源支持和 LAION 的数据资源支持,Stable Diffusion 在 LAION-5B 的一个子集上训练了一个 Latent Diffusion Models,该模型专门用于文图生成。Latent Diffusion Models 通过在一个潜在表示空间中迭代“去噪”数据来生成图像,然后将表示结果解码为完整的图像,让文图生成能够在消费级 GPU 上,在10秒级别时间生成图片,大大降低了落地门槛,也带来了文图生成领域的大火。所以,如果你想了解 Stable Diffusion 的背后原理,可以先深入解读一下其背后的论文 High-Resolution Image Synthesis with Latent Diffusion Models。如果你想了解更多关于 Stable Diffusion 模型的信息,你可以查看由 🤗Huggingface 团队撰写的相关博客。
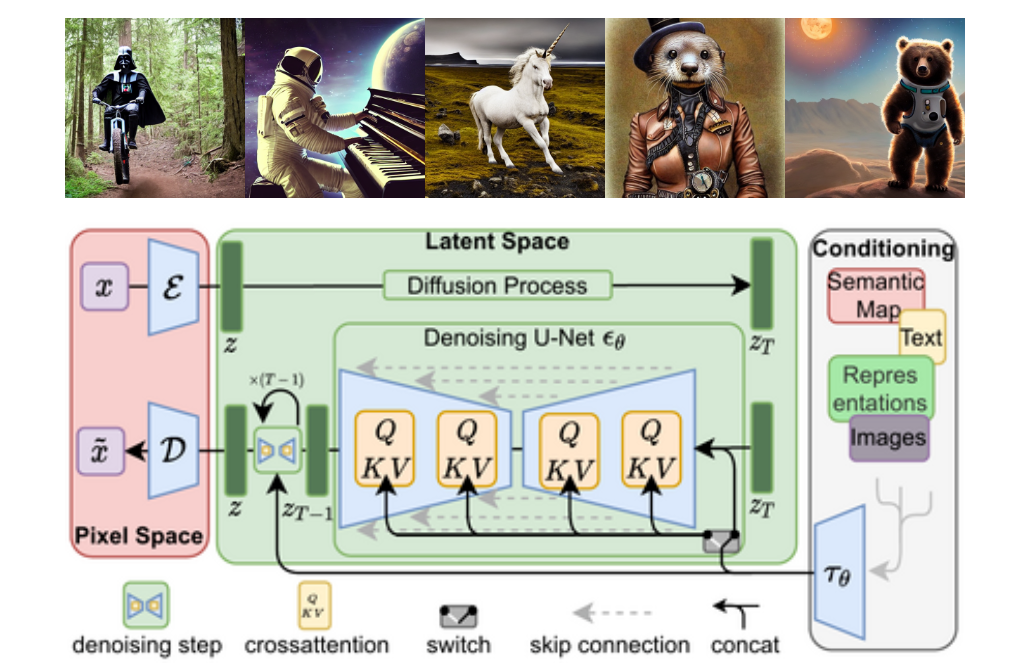
注:模型结构图引自CompVis/latent-diffusion仓库,生成图片引用自CompVis/stable-diffusion仓库。
Stable Diffusion Model Zoo
环境准备
创建新的终端
通过conda 创建实验环境
conda create -n paddle python=3.10随后执行conda init ,在新的终端切换到虚拟环境
conda activate paddle安装ppdiffusers可以通过源码安装或者pip直接安装
ppdiffusers的安装
源码安装
通过 git clone 命令拉取 PaddleMIX 源码,并安装必要的依赖库。
# 克隆 PaddleMIX 仓库
git clone https://github.com/PaddlePaddle/PaddleMIX.git
cd PaddleMIX
# 切换到对应分支
git checkout ppdiffusers0.24.1
# 进入ppdiffuers目录
cd ppdiffusers
# 安装所需的依赖, 如果提示权限不够,请在最后增加 --user 选项
pip install -e .注:本模型训练与推理需要依赖 CUDA 11.2 及以上版本,如果本地机器不符合要求,建议前往 AI Studio 进行模型训练、推理任务。推荐使用Linux系统,Windows系统未经过系统测试。
pip安装
pip install ppdiffusers==0.24.1PaddlePaddle安装
aistudio中的显卡cuda版本为11.8

前往官网安装对应的paddlepaddle-gpu,我安装的版本是2.6.1
python -m pip install paddlepaddle-gpu==2.6.1 -i https://pypi.tuna.tsinghua.edu.cn/simplehuggingface-hub降版本
注意huggingface-hub版本是0.23.0
使用pip list | grep hugging 查看

如果不是这个版本
使用pip install huggingface-hub==0.23.0安装
数据准备
预训练 Stable Diffusion 使用 Laion400M 数据集,需要自行下载和处理,处理步骤详见 自定义训练数据。本教程为了方便大家 体验跑通训练流程,提供了处理后的 Laion400M 部分数据集,可直接下载获取.
使用 Laion400M 数据集
部分数据,约1000条,仅供验证跑通训练
demo 数据可通过如下命令下载与解压:
cd ~/PaddleMIX/ppdiffusers/examples/stable_diffusion
# 删除当前目录下的data
rm -rf data
# 下载 laion400m_demo 数据集
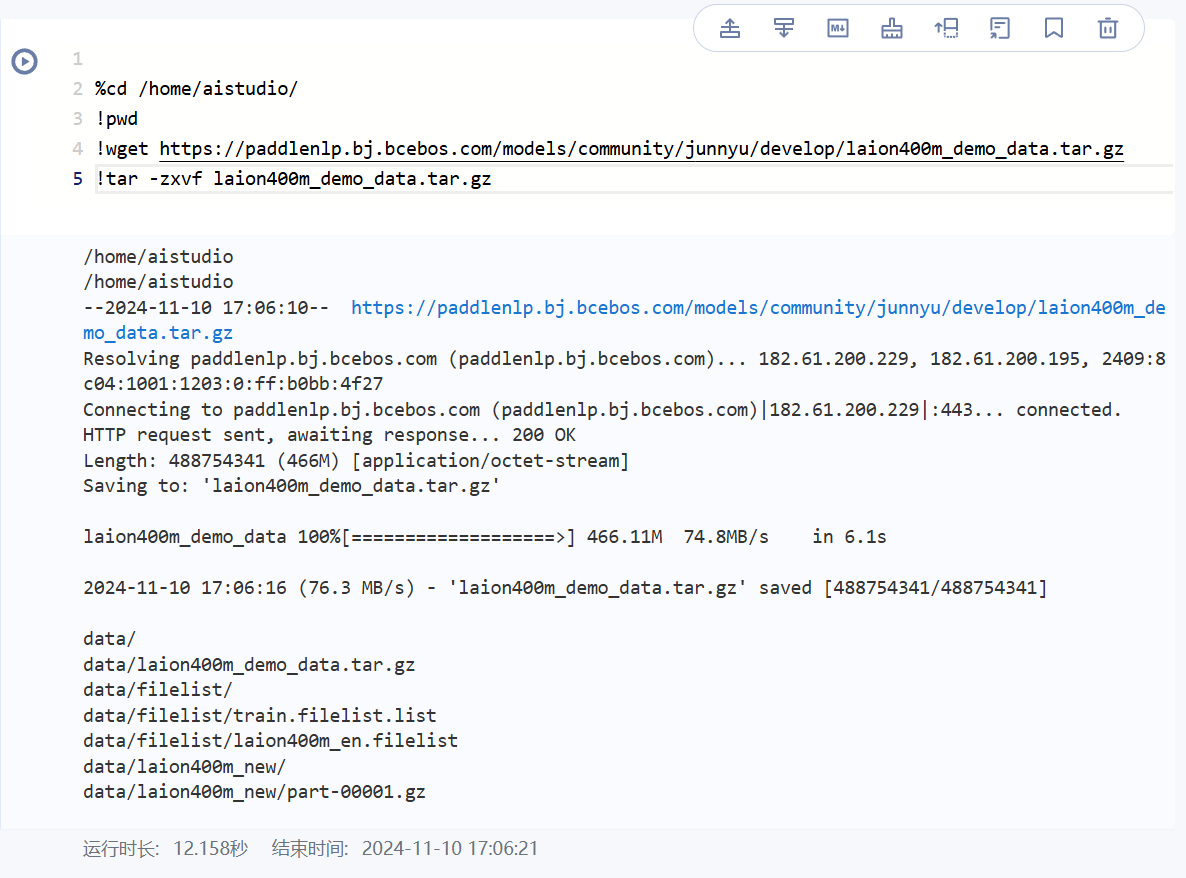
wget https://paddlenlp.bj.bcebos.com/models/community/junnyu/develop/laion400m_demo_data.tar.gz
# 解压
tar -zxvf laion400m_demo_data.tar.gz解压后文件目录如下所示:
data
├── filelist
| ├── train.filelist.list
| └── laion400m_en.filelist
├── laion400m_new
| └── part-00001.gz
└── laion400m_demo_data.tar.gz # 多余的压缩包,可以删除
laion400m_en.filelist 是数据索引文件,包含了6000行数据文件的路径(part-00001.gz 仅为部分数据),内容如下所示:
./data/laion400m_new/part-00001.gz
./data/laion400m_new/part-00001.gz
./data/laion400m_new/part-00001.gz
./data/laion400m_new/part-00001.gz
./data/laion400m_new/part-00001.gz
./data/laion400m_new/part-00001.gz
./data/laion400m_new/part-00001.gz
...
自定义训练数据
如果需要自定义数据,推荐沿用coco_karpathy数据格式处理自己的数据。其中每条数据标注格式示例为:
{"caption": "A woman wearing a net on her head cutting a cake. ", "image": "val2014/COCO_val2014_000000522418.jpg", "image_id": "coco_522418"}
在准备好自定义数据集以后,我们可以使用 create_pretraining_data.py 生成我们需要的数据。
python create_pretraining_data.py \
--input_path ./coco_data/coco_data.jsonl \
--output_path ./processed_data \
--caption_key "caption" \
--image_key "image" \
--per_part_file_num 1000 \
--num_repeat 100 \
--save_gzip_filecreate_pretraining_data.py 可传入的参数解释如下:
--input_path: 输入的 jsonl 文件路径,可以查看coco_data文件夹的组织结构,自定义我们自己的数据。--output_path: 处理后的数据保存路径。--output_name: 输出文件的名称,默认为custom_dataset。--caption_key: jsonl文件中,每一行数据表示文本的 key 值,默认为caption。--image_key: jsonl文件中,每一行数据表示图片的 key 值,默认为image。--per_part_file_num: 每个part文件保存的数据数量,默认为1000。--save_gzip_file: 是否将文件保存为gzip的格式,默认为False。--num_repeat:custom_dataset.filelist文件中part数据的重复次数,默认为1。当前我们设置成100是为了能够制造更多的part数据,可以防止程序运行时会卡住,如果用户有很多数据的时候,无需修改该默认值。
运行上述命令后,会生成 ./processed_data 文件夹。
processed_data
├── filelist
| ├── custom_dataset.filelist.list
| └── custom_dataset.filelist
└── laion400m_format_data
└── part-000001.gz
processed_data/custom_dataset.filelist 是数据索引文件,包含100行数据,每行都代表一个数据文件的路径。请确保该文件的行数足够多,以防止在训练过程中出现卡顿,内容如下所示:
processed_data/laion400m_format_data/part-000001.gz
processed_data/laion400m_format_data/part-000001.gz
processed_data/laion400m_format_data/part-000001.gz
processed_data/laion400m_format_data/part-000001.gz
processed_data/laion400m_format_data/part-000001.gz
processed_data/laion400m_format_data/part-000001.gz
processed_data/laion400m_format_data/part-000001.gz
processed_data/laion400m_format_data/part-000001.gz
...
processed_data/custom_dataset.filelist.list 为filelist索引文件,内容如下所示:
processed_data/filelist/custom_dataset.filelist
processed_data/laion400m_format_data/part-000001.gz 为实际的数据文件,内容结构如下所示:
每一行以"\t"进行分割,第一列为 caption文本描述, 第二列为 占位符空, 第三列为 base64编码的图片,示例:caption, _, img_b64 = vec[:3]
开始训练
我们~/PaddleMIX/ppdiffusers/examples/stable_diffusion 下创建train.sh
由于aistudio中写shell脚本无法识别export指令与换行符,所以我修改了一下train.sh。环境变量可以在~/.bashrc 在添加(也可以不添加,因为是单卡)。
注意batch_size改成16,不然会爆显存。然后save_steps 可以酌情更改,默认训练10000步保存一次。具体参数参考文档。
#!/bin/bash
# export FLAG_FUSED_LINEAR=0
# export FLAGS_conv_workspace_size_limit=4096
# 是否开启 ema
# export FLAG_USE_EMA=0
# 是否开启 recompute
# export FLAG_RECOMPUTE=1
# 是否开启 xformers
# export FLAG_XFORMERS=1
# 如果使用自定义数据
#FILE_LIST=./processed_data/filelist/custom_dataset.filelist.list
# 如果使用laion400m_demo数据集,需要把下面的注释取消
#FILE_LIST=/home/aistudio/data/filelist/train.filelist.list
python -u train_txt2img_laion400m_trainer.py --do_train --output_dir ./laion400m_pretrain_output_trainer --per_device_train_batch_size 16 --gradient_accumulation_steps 1 --learning_rate 1e-4 --weight_decay 0.01 --max_steps 200000 --lr_scheduler_type "constant" --warmup_steps 0 --image_logging_steps 1000 --logging_steps 10 --resolution 256 --save_steps 10000 --save_total_limit 20 --seed 23 --dataloader_num_workers 4 --vae_name_or_path CompVis/stable-diffusion-v1-4/vae --text_encoder_name_or_path CompVis/stable-diffusion-v1-4/text_encoder --unet_name_or_path ./sd/unet_config.json --file_list ./data/filelist/train.filelist.list --model_max_length 77 --max_grad_norm -1 --disable_tqdm True --bf16 False --overwrite_output_dir
随后就可以运行脚本开始训练
bash train.sh
训练完成后,会在输出路径保存模型。
推理
直接加载模型参数推理
未经完整训练,直接加载公开发布的模型参数进行推理。
from ppdiffusers import StableDiffusionPipeline, UNet2DConditionModel
# 加载公开发布的 unet 权重
unet_model_name_or_path = "CompVis/stable-diffusion-v1-4/unet"
unet = UNet2DConditionModel.from_pretrained(unet_model_name_or_path)
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", safety_checker=None, unet=unet)
prompt = "a photo of an astronaut riding a horse on mars" # or a little girl dances in the cherry blossom rain
image = pipe(prompt, guidance_scale=7.5, width=512, height=512).images[0]
image.save("astronaut_rides_horse.png")使用训练的模型参数进行推理
待模型训练完毕,会在 output_dir 保存训练好的模型权重,使用自行训练后生成的模型参数进行推理。
from ppdiffusers import StableDiffusionPipeline, UNet2DConditionModel
# 加载上面我们训练好的 unet 权重
unet_model_name_or_path = "./laion400m_pretrain_output_trainer/checkpoint-5000/unet"
unet = UNet2DConditionModel.from_pretrained(unet_model_name_or_path)
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", safety_checker=None, unet=unet)
prompt = "a photo of an astronaut riding a horse on mars"
# 当前训练的是256x256分辨率图片,因此请确保训练和推理参数最好一致
image = pipe(prompt, guidance_scale=7.5, width=256, height=256).images[0]
image.save("astronaut_rides_horse.png")最后得到推理图片

- 感谢你赐予我前进的力量
-
微信
- 支付宝