
动手学深度学习v2(2.3)线性代数
本文最后更新于 2024-11-12,文章内容可能已经过时。
标量
如果你曾经在餐厅支付餐费,那么应该已经知道一些基本的线性代数,比如在数字间相加或相乘。例如,北京的温度为52∘F(华氏度,除摄氏度外的另一种温度计量单位)。严格来说,仅包含一个数值被称为标量(scalar)。如果要将此华氏度值转换为更常用的摄氏度,则可以计算表达式c=95(f−32),并将f赋为52。在此等式中,每一项(5、9和32)都是标量值。符号c和f称为变量(variable),它们表示未知的标量值。
本书采用了数学表示法,其中标量变量由普通小写字母表示(例如,x、y和z)。本书用R表示所有(连续)实数标量的空间,之后将严格定义空间(space)是什么,但现在只要记住表达式x∈R是表示x是一个实值标量的正式形式。符号∈称为“属于”,它表示“是集合中的成员”。例如x,y∈{0,1}可以用来表明x和y是值只能为0或1的数字。
标量由只有一个元素的张量表示。下面的代码将实例化两个标量,并执行一些熟悉的算术运算,即加法、乘法、除法和指数。
import torch
x = torch.tensor(3.0)
y = torch.tensor(2.0)
x + y, x * y, x / y, x**y
向量
向量可以被视为标量值组成的列表。 这些标量值被称为向量的元素(element)或分量(component)。 当向量表示数据集中的样本时,它们的值具有一定的现实意义。 例如,如果我们正在训练一个模型来预测贷款违约风险,可能会将每个申请人与一个向量相关联, 其分量与其收入、工作年限、过往违约次数和其他因素相对应。 如果我们正在研究医院患者可能面临的心脏病发作风险,可能会用一个向量来表示每个患者, 其分量为最近的生命体征、胆固醇水平、每天运动时间等。 在数学表示法中,向量通常记为粗体、小写的符号 (例如,x、y和z))。
人们通过一维张量表示向量。一般来说,张量可以具有任意长度,取决于机器的内存限制。
x = torch.arange(4)
x
我们可以使用下标来引用向量的任一元素,例如可以通过x_i来引用第i个元素。 注意,元素x_i是一个标量,所以我们在引用它时不会加粗。 大量文献认为列向量是向量的默认方向,在本书中也是如此。 在数学中,向量x可以写为:
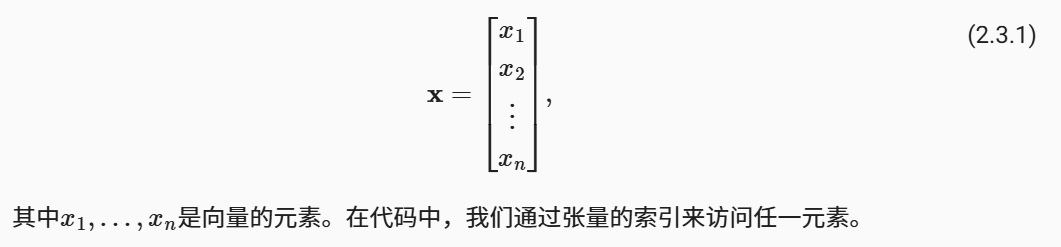
x[3]
长度、维度和形状
向量只是一个数字数组,就像每个数组都有一个长度一样,每个向量也是如此。 在数学表示法中,如果我们想说一个向量x由n个实值标量组成, 可以将其表示为x∈R^n。 向量的长度通常称为向量的维度(dimension)。
与普通的Python数组一样,我们可以通过调用Python的内置len()函数来访问张量的长度。
len(x)
当用张量表示一个向量(只有一个轴)时,我们也可以通过.shape属性访问向量的长度。 形状(shape)是一个元素组,列出了张量沿每个轴的长度(维数)。 对于只有一个轴的张量,形状只有一个元素。
x.shape
请注意,维度(dimension)这个词在不同上下文时往往会有不同的含义,这经常会使人感到困惑。 为了清楚起见,我们在此明确一下: 向量或轴的维度被用来表示向量或轴的长度,即向量或轴的元素数量。 然而,张量的维度用来表示张量具有的轴数。 在这个意义上,张量的某个轴的维数就是这个轴的长度。
矩阵
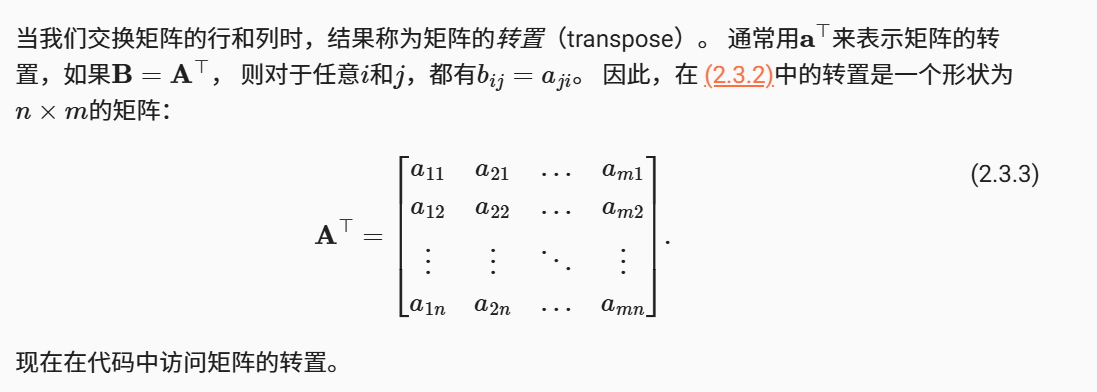
正如向量将标量从零阶推广到一阶,矩阵将向量从一阶推广到二阶。 矩阵,我们通常用粗体、大写字母来表示 (例如,X、Y和Z), 在代码中表示为具有两个轴的张量。

A = torch.arange(20).reshape(5, 4)
A
A.T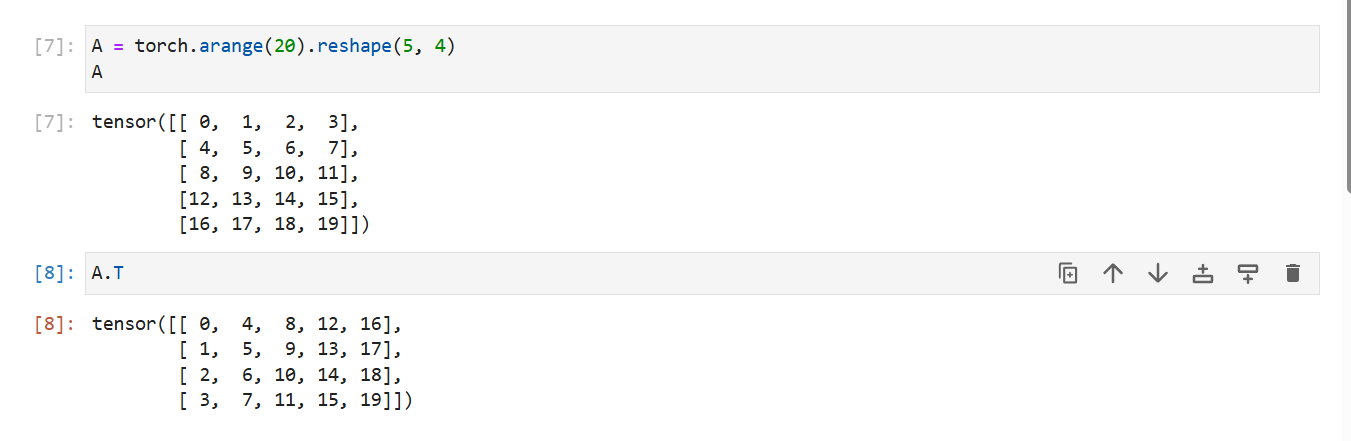

B = torch.tensor([[1, 2, 3], [2, 0, 4], [3, 4, 5]])
B
现在我们将B与它的转置进行比较。
B == B.T
矩阵是有用的数据结构:它们允许我们组织具有不同模式的数据。 例如,我们矩阵中的行可能对应于不同的房屋(数据样本),而列可能对应于不同的属性。 曾经使用过电子表格软件或已阅读过 2.2节的人,应该对此很熟悉。 因此,尽管单个向量的默认方向是列向量,但在表示表格数据集的矩阵中, 将每个数据样本作为矩阵中的行向量更为常见。 后面的章节将讲到这点,这种约定将支持常见的深度学习实践。 例如,沿着张量的最外轴,我们可以访问或遍历小批量的数据样本。
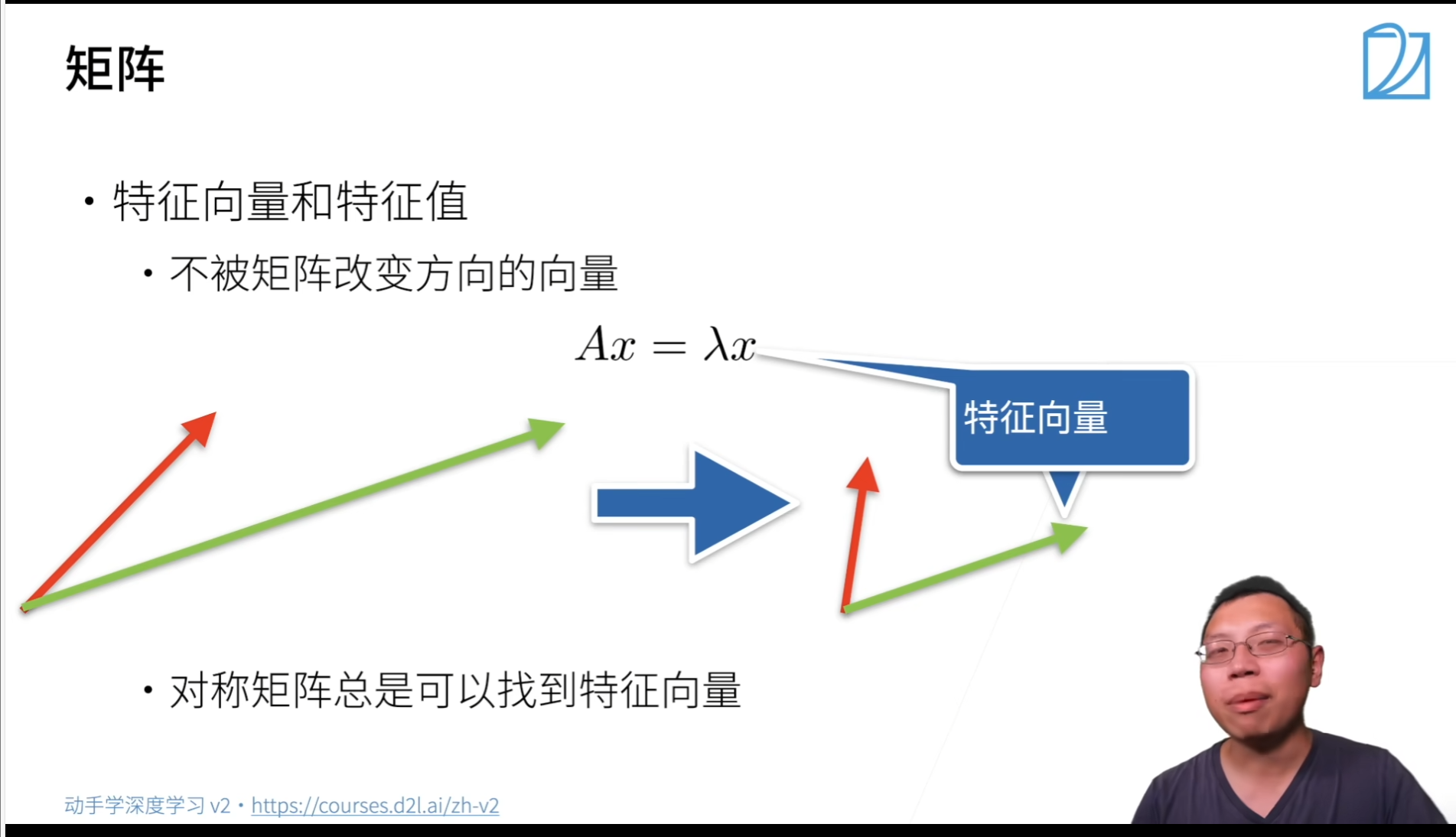
特征向量
张量

当我们开始处理图像时,张量将变得更加重要,图像以n维数组形式出现, 其中3个轴对应于高度、宽度,以及一个通道(channel)轴, 用于表示颜色通道(红色、绿色和蓝色)。 现在先将高阶张量暂放一边,而是专注学习其基础知识。
X = torch.arange(24).reshape(2, 3, 4)
X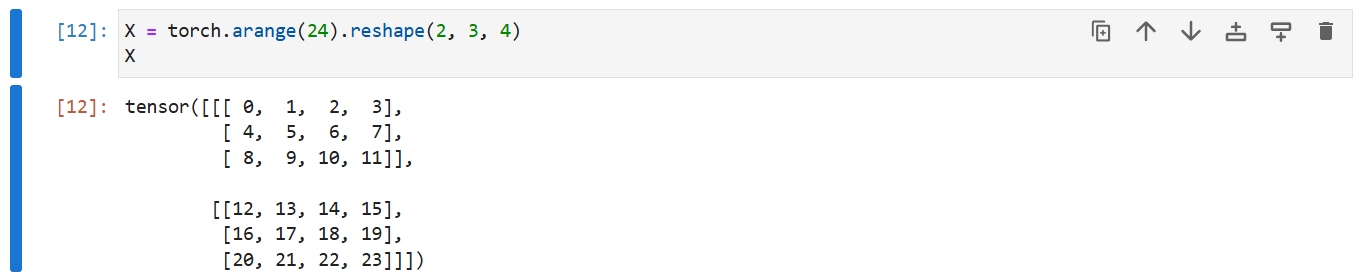
张量算法的基本性质
标量、向量、矩阵和任意数量轴的张量(本小节中的“张量”指代数对象)有一些实用的属性。 例如,从按元素操作的定义中可以注意到,任何按元素的一元运算都不会改变其操作数的形状。 同样,给定具有相同形状的任意两个张量,任何按元素二元运算的结果都将是相同形状的张量。 例如,将两个相同形状的矩阵相加,会在这两个矩阵上执行元素加法。
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
B = A.clone() # 通过分配新内存,将A的一个副本分配给B
A, A + B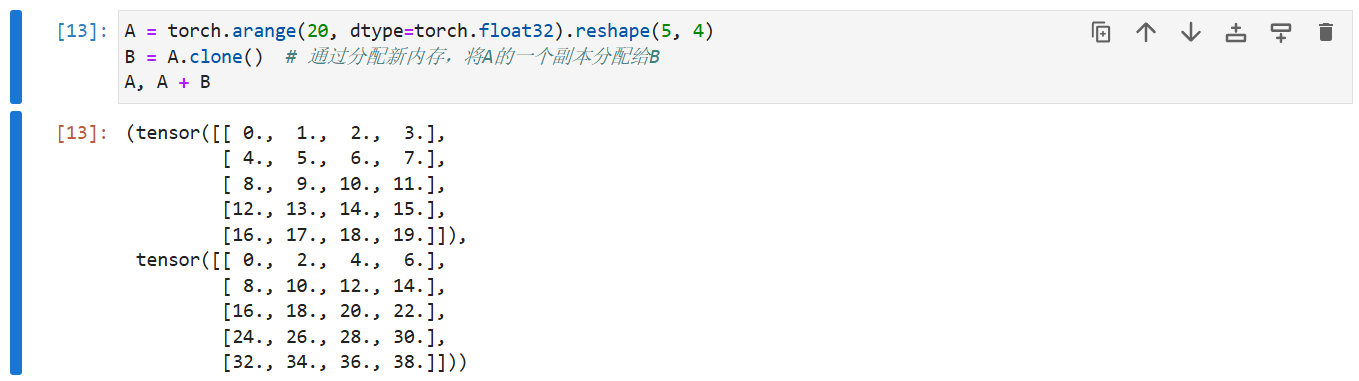

A * B
将张量乘以或加上一个标量不会改变张量的形状,其中张量的每个元素都将与标量相加或相乘。
a = 2
X = torch.arange(24).reshape(2, 3, 4)
a + X, (a * X).shape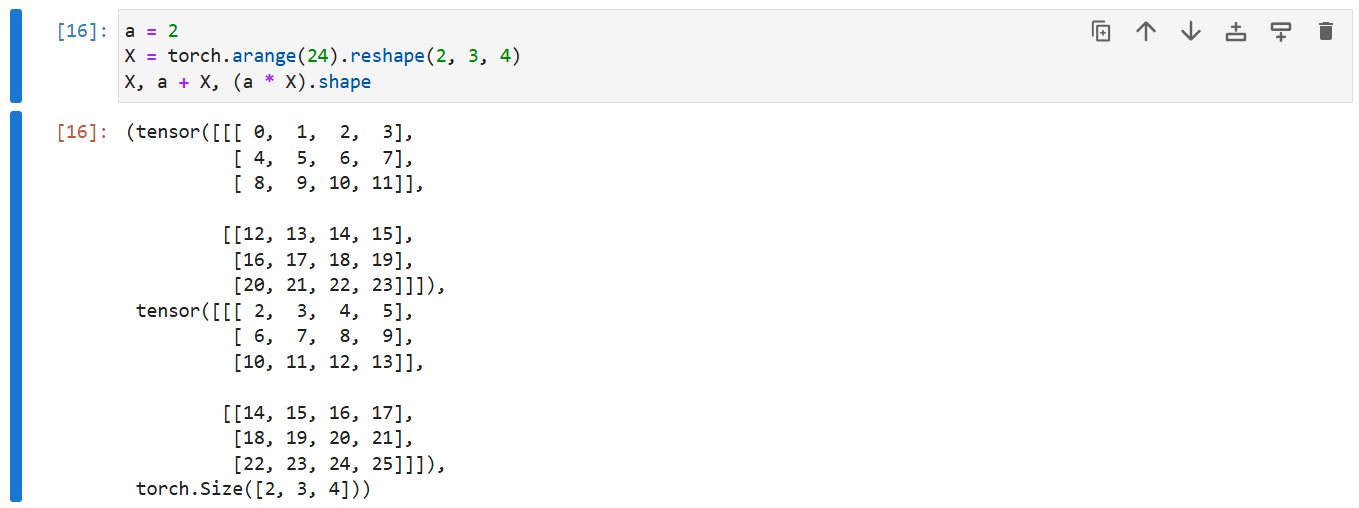
降维

x = torch.arange(4, dtype=torch.float32)
x, x.sum()

A.shape, A.sum()

默认情况下,调用求和函数会沿所有的轴降低张量的维度,使它变为一个标量。 我们还可以指定张量沿哪一个轴来通过求和降低维度。 以矩阵为例,为了通过求和所有行的元素来降维(轴0),可以在调用函数时指定axis=0。 由于输入矩阵沿0轴降维以生成输出向量,因此输入轴0的维数在输出形状中消失。
A_sum_axis0 = A.sum(axis=0)
A_sum_axis0, A_sum_axis0.shape
指定axis=1将通过汇总所有列的元素降维(轴1)。因此,输入轴1的维数在输出形状中消失。
A_sum_axis1 = A.sum(axis=1)
A_sum_axis1, A_sum_axis1.shape
沿着行和列对矩阵求和,等价于对矩阵的所有元素进行求和。
A.sum(axis=[0, 1]) # 结果和A.sum()相同
一个与求和相关的量是平均值(mean或average)。 我们通过将总和除以元素总数来计算平均值。 在代码中,我们可以调用函数来计算任意形状张量的平均值。
A.mean(), A.sum() / A.numel()
同样,计算平均值的函数也可以沿指定轴降低张量的维度。
A.mean(axis=0), A.sum(axis=0) / A.shape[0]
非降维求和
但是,有时在调用函数来计算总和或均值时保持轴数不变会很有用。
sum_A = A.sum(axis=1, keepdims=True)
sum_A, sum_A.shape
例如,由于sum_A在对每行进行求和后仍保持两个轴,我们可以通过广播将A除以sum_A。
A / sum_A如果我们想沿某个轴计算A元素的累积总和, 比如axis=0(按行计算),可以调用cumsum函数。 此函数不会沿任何轴降低输入张量的维度。
A.cumsum(axis=0)
点积

y = torch.ones(4, dtype = torch.float32)
x, y, torch.dot(x, y)
注意,我们可以通过执行按元素乘法,然后进行求和来表示两个向量的点积:
torch.sum(x * y)

矩阵-向量积
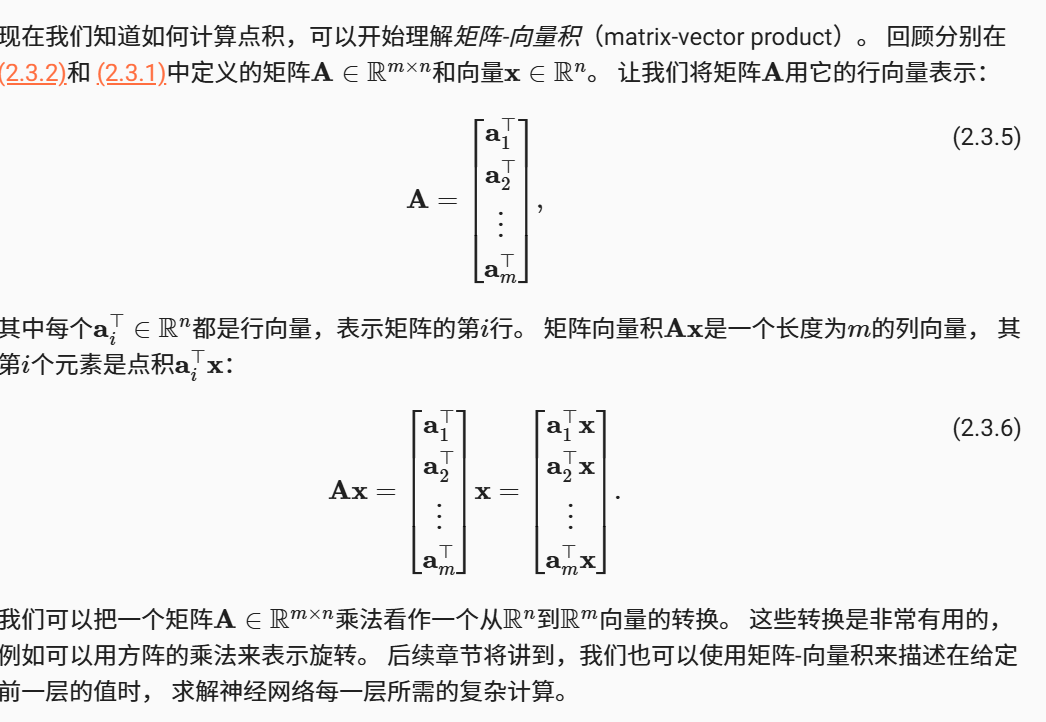
在代码中使用张量表示矩阵-向量积,我们使用mv函数。 当我们为矩阵A和向量x调用torch.mv(A, x)时,会执行矩阵-向量积。 注意,A的列维数(沿轴1的长度)必须与x的维数(其长度)相同。
A.shape, x.shape, torch.mv(A, x)
矩阵-矩阵乘法

我们可以将矩阵-矩阵乘法AB看作简单地执行m次矩阵-向量积,并将结果拼接在一起,形成一个n×m矩阵。 在下面的代码中,我们在A和B上执行矩阵乘法。 这里的A是一个5行4列的矩阵,B是一个4行3列的矩阵。 两者相乘后,我们得到了一个5行3列的矩阵。
B = torch.ones(4, 3)
torch.mm(A, B)
矩阵-矩阵乘法可以简单地称为矩阵乘法,不应与“Hadamard积”混淆。
范数
线性代数中最有用的一些运算符是范数(norm)。 非正式地说,向量的范数是表示一个向量有多大。 这里考虑的大小(size)概念不涉及维度,而是分量的大小。

u = torch.tensor([3.0, -4.0])
torch.norm(u)

torch.abs(u).sum()

torch.norm(torch.ones((4, 9)))
范数与目标
在深度学习中,我们经常试图解决优化问题: 最大化分配给观测数据的概率; 最小化预测和真实观测之间的距离。 用向量表示物品(如单词、产品或新闻文章),以便最小化相似项目之间的距离,最大化不同项目之间的距离。 目标,或许是深度学习算法最重要的组成部分(除了数据),通常被表达为范数。
关于线性代数的更多信息
仅用一节,我们就教会了阅读本书所需的、用以理解现代深度学习的线性代数。 线性代数还有很多,其中很多数学对于机器学习非常有用。 例如,矩阵可以分解为因子,这些分解可以显示真实世界数据集中的低维结构。 机器学习的整个子领域都侧重于使用矩阵分解及其向高阶张量的泛化,来发现数据集中的结构并解决预测问题。 当开始动手尝试并在真实数据集上应用了有效的机器学习模型,你会更倾向于学习更多数学。 因此,这一节到此结束,本书将在后面介绍更多数学知识。
如果渴望了解有关线性代数的更多信息,可以参考线性代数运算的在线附录或其他优秀资源 (Kolter, 2008, Petersen et al., 2008, Strang, 1993)。
小结
标量、向量、矩阵和张量是线性代数中的基本数学对象。
向量泛化自标量,矩阵泛化自向量。
标量、向量、矩阵和张量分别具有零、一、二和任意数量的轴。
一个张量可以通过
sum和mean沿指定的轴降低维度。两个矩阵的按元素乘法被称为他们的Hadamard积。它与矩阵乘法不同。
在深度学习中,我们经常使用范数,如L1范数、L2范数和Frobenius范数。
我们可以对标量、向量、矩阵和张量执行各种操作。
练习
证明一个矩阵A的转置的转置是A,即(A⊤)⊤=A。
给出两个矩阵A和B,证明“它们转置的和”等于“它们和的转置”,即A⊤+B⊤=(A+B)⊤。
给定任意方阵A,A+A⊤总是对称的吗?为什么?
本节中定义了形状(2,3,4)的张量
X。len(X)的输出结果是什么?对于任意形状的张量
X,len(X)是否总是对应于X特定轴的长度?这个轴是什么?运行
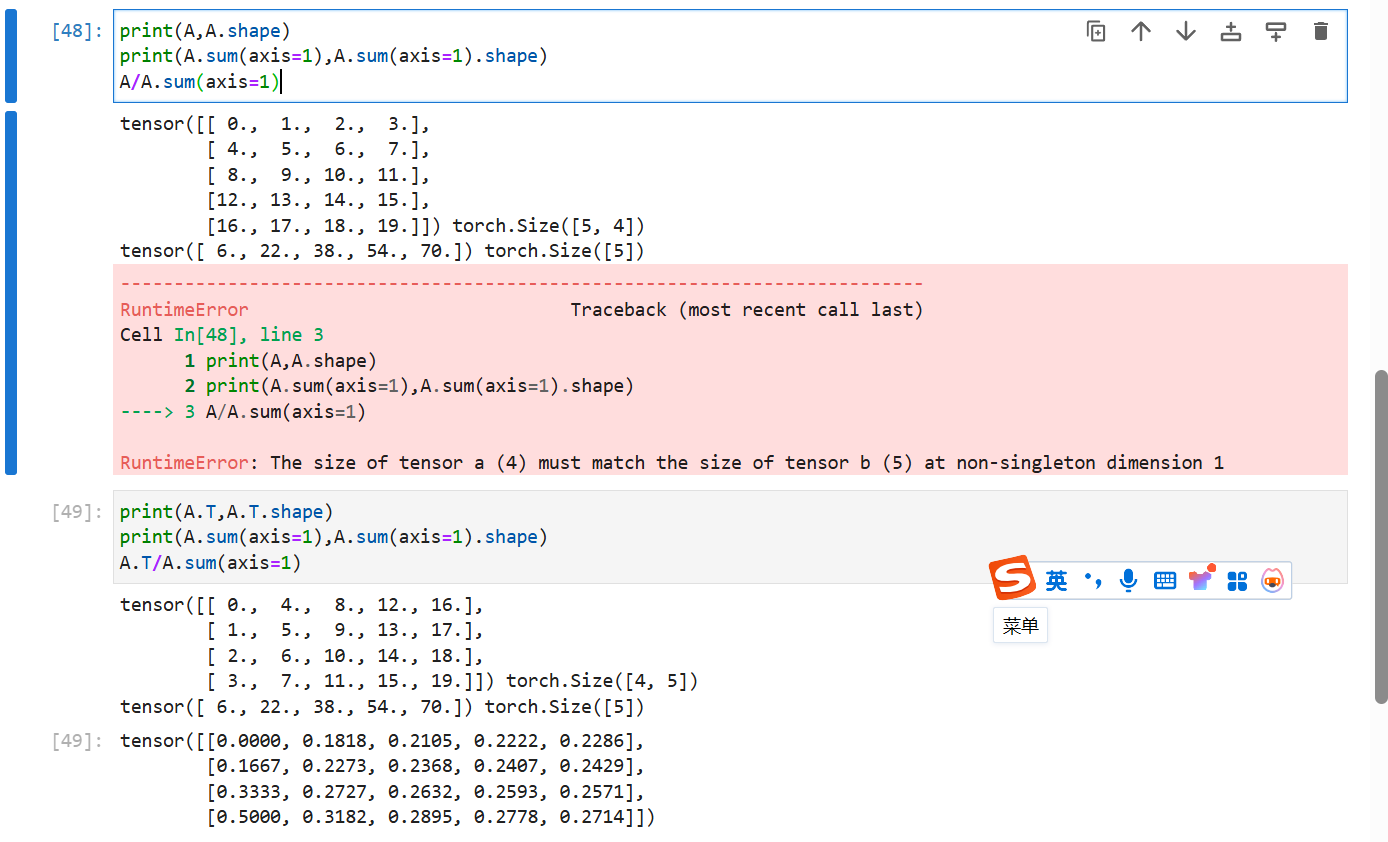
A/A.sum(axis=1),看看会发生什么。请分析一下原因?考虑一个具有形状(2,3,4)的张量,在轴0、1、2上的求和输出是什么形状?
为
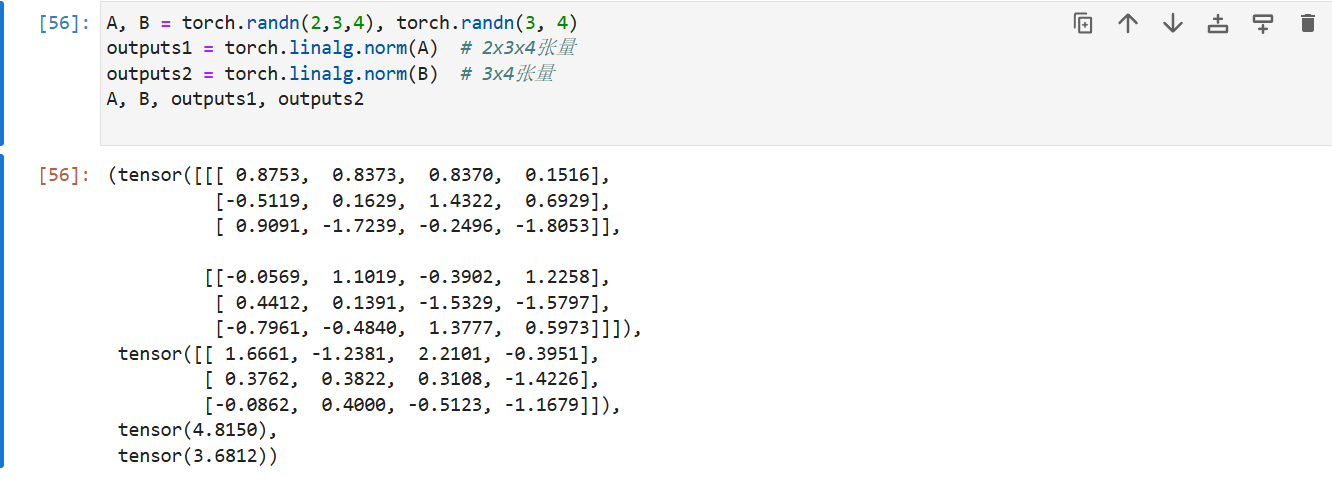
linalg.norm函数提供3个或更多轴的张量,并观察其输出。对于任意形状的张量这个函数计算得到什么?
答案
1.略
2.略
3.是的
4.
5.是的,len(X)对应X最外层轴axis0的长度
6.维度不匹配,无法使用广播机制
7.
8.
问题
- 感谢你赐予我前进的力量
-
微信
- 支付宝