
图像基础美学(三)深度学习美学质量评估方法
本文最后更新于 2024-10-29,文章内容可能已经过时。
从大量数据中学习特征已经在识别、定位、跟踪等任务上表现出越来越好的性能,超越了传统的人工设计特征。越来越多的研究者们也开始采用深度学习方法学习图像美学特征,本节介绍相关进展。
我们给大家介绍过,图像美学质量评估问题可以作为分类问题、回归问题、排序问题来进行研究,下面我们分别对这3类模型的发展进行介绍。
分类模型
利用深度学习方法,研究者即使没有丰富的图像美学和摄影知识也可以完成图像美学质量评估任务模型的训练,且其性能要好于人工设计特征。
单输入模型
一个基本的图像美学质量评后模型架构如图2.8所示。
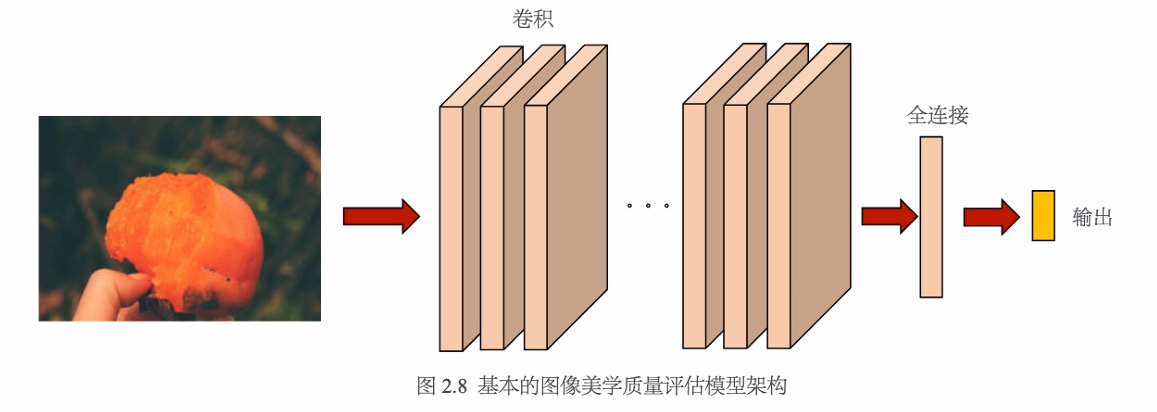
上述模型架构是一个常见的图像分类或者回归模型架构,由于美学数据集较小,可以采用从其他任务,如ImageNet分类任务中学习到的通用深度特征进行初始化,然后为美学质量评估任务训练新的分类器或回归模型。
另外,还可以使用模型本身的多尺度信息,即融合不同层、不同感受来获取全局和局部的特征,这在图像分割模型UNet和目标检测模型SSD中被证明可以有效改进模型的学习能力。
多输入模型
为了获得更好的结果,Lu等人提出了 RAPID模型,它们将全局和局部 CNN堆叠在一起形成双列CNN(DCNN),分别输入全局图和局部图。全局图有利于捕捉主体信息,而局部图有利于捕捉局部细节。RAPID模型使用类似AlexNet的架构,两个子网络的输出层(即全连接层)进行拼接得到最终特征,然后进行分类,优化目标采用Softmax损失。RAPID模型架构如图2.9所示。
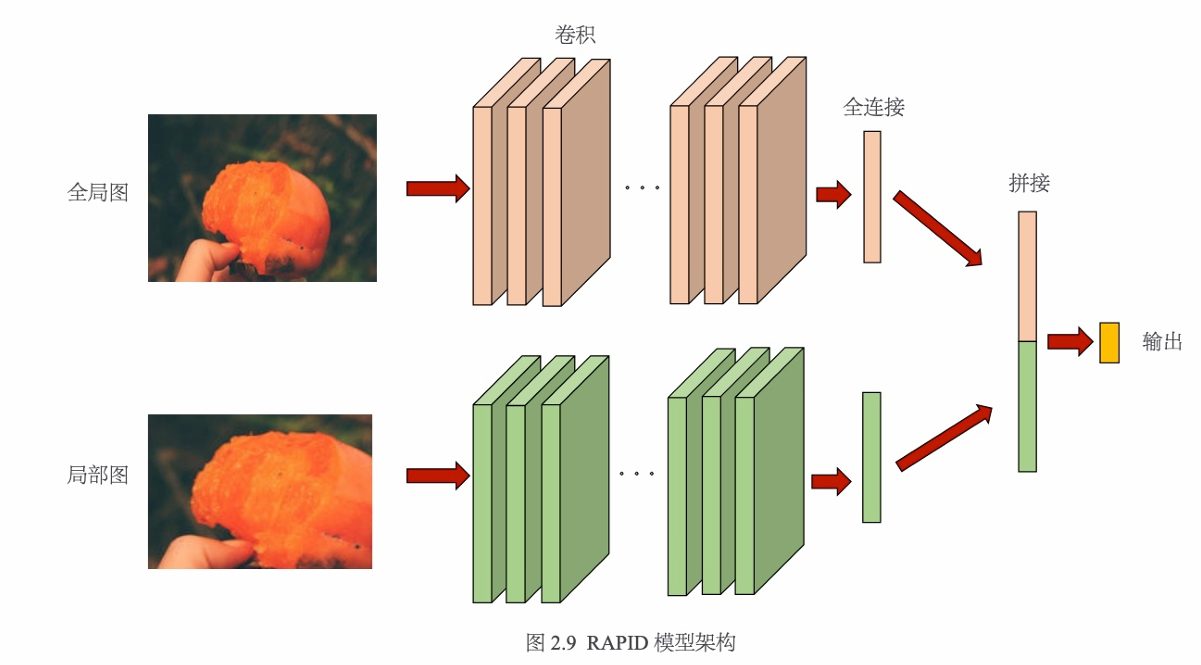
另外,在RAPID模型中还可以通过增加风格输入来进一步提高网络的能力。由于AVA数据集中带语义标签的图像较少,笔者使用了预先训练好的风格网络来提取风格向量,然后和美学网络提取的特征向量拼接以作为最后的特征向量,在这个过程中风格向量相当于一个正则项。
Wang等人提出了一种被称为BDN的多列CNN模型。与RAPID模型不同的是,BDN模型预先训练了多个不同风格的分类CNN模型而不是单个风格的分类CNN模型,这些模型与图像的亮度、色度底层信息一起并行级联作为CNN的输入来预测图像的美学质量分数和分布。
在DMA模型中,来自多个随机采样的图像块被送入包括4个卷积层和3个全连接层的单路卷积神经网络。为了组合来自采样图像块的特征输出,设计了一个统计聚集结构(Odderless Multi-Patch Aggregation),在该结构中使用了最小、最大、中值和平均池化方法对CNN的特征进行聚合,最后输出Softmax概率到分类层。DMA模型架构如图2.10所示。
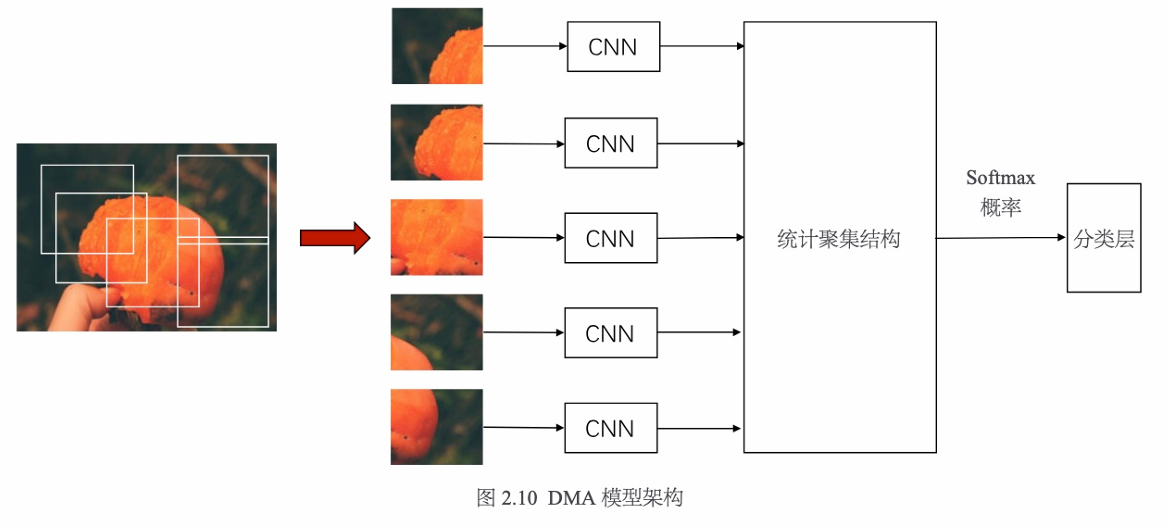
实际上随机选择图像块并非是最优的方案,因为我们不对整个图像的内容感兴趣,所以对于DMA模型的最简单的改进,就是使用显著目标检测等方法预先确定图像主体目标,然后根据一系列构图方法来选择附近有意义的图像子块。显著目标检测方法将会在第3章中介绍。
以上的模型或缩放了图像分辨率,或裁剪了子图,这改变了原图的美学特性。因此Mai等人借鉴SPPNet中的自适应空间池化技术,在最后的卷积层之后,使用了多路不同感受野大小的固定长度的输出,不仅有效地编码了多尺度图像信息,还可以在训练和测试时适应任意大小的输入。不过多尺度特征可能包括冗余或重叠的信息,并且可能导致网络过拟合。
回归模型
虽然使用分类模型可以较好地分类出高美学质量图和低美学质量图,但有时候我们要得到的是美学质量分数的定量结果,而不仅仅是一个分类结果,此时需要使用回归模型。
基本的回归模型与上述的分类模型结构一致,只是标签和预测结果值由美学分类类别换成了具体的分数值,优化目标由交叉熵损失换成了欧氏距离等损失。
然而,预测具体的美学质量分数很容易过拟合,因为不同人的标注结果有很大差异。在AVA数据集中,一张图像的标注结果由多个人完成,因此标注结果是一个分布,而不是单一的值。基于此,Google的研究团队提出了NIMA模型,它预测美学质量的分数分布概率,分数值为1~10。
该研究团队使用的NIMA模型架构如图2.11所示,分类网络的最后一层被全连接层取代,输出10个分数的分布。
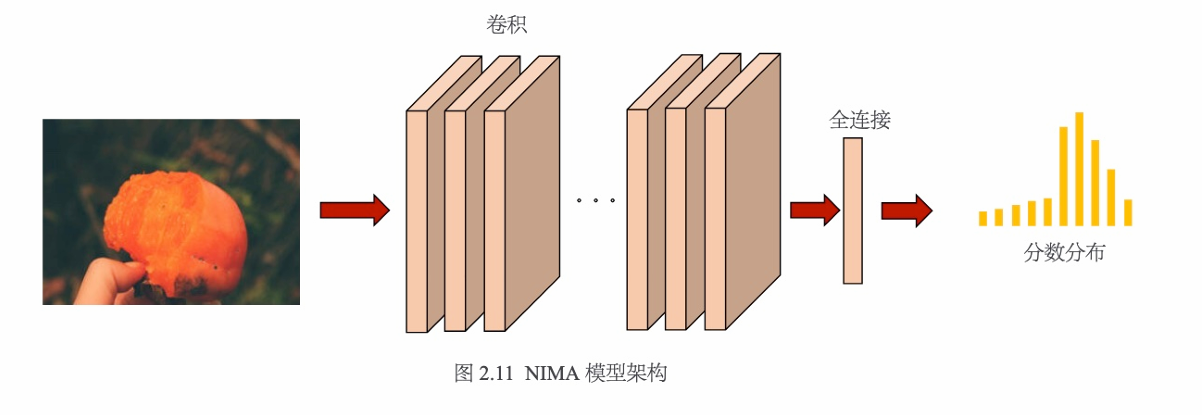
对于NIMA模型,可以使用欧氏距离作为优化目标,但是使用KL散度、卡方距离(Chi-square Distance)、推土机距离(Earth Mover's Distance)等是更好的选择,因为它们更适合用于评估两个分布的相似性。
排序模型
前面说过判断单张图像的美学类别或者美学质量分数是比较困难的,然而比较两张图像的相对美学较容易,因此排序模型也是一种研究美学的方案。
Kong等人提出了以图像对为输入的Siamese模型,其架构如图2.12所示。
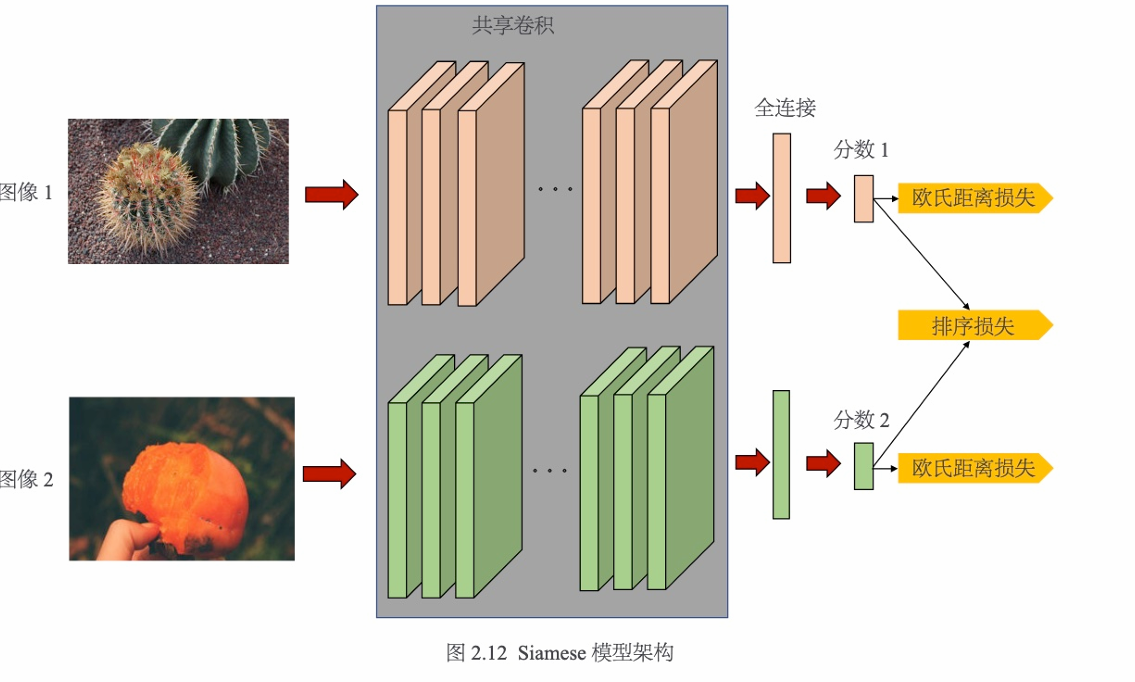
训练的时候分多步进行。
在第1阶段,基础网络在美学数据集上预训练并进行微调,这一阶段使用欧氏距离作为优化目标。之后,Siamese模型对每个采样图像对的损失进行排序。收敛后,微调的基础网络被用作初步特征提取器。
在第2阶段,将属性预测分支添加到基础网络以预测图像属性信息,然后通过结合评分的欧氏距离损失、属性分类损失和排序损失,使用多任务方式继续对基础网络进行微调。
在第3阶段,另一个内容分类分支被添加到基础网络以预测预定义的一组类别标签。收敛时,内容分类预测的Softmax输出作为加权向量,用于加权每个特征分支(美学分支、属性分支和内容分支)产生的分数。
在第4阶段,将带有额外分支的基础网络与固定的内容分类分支一起进行微调。
实验结果表明,通过考虑属性和类别内容信息来学习美学特征是非常有效的。
对于排序模型,我们不仅可以使用Siamese模型,也可以使用Triplet模型,感兴趣的读者可以阅读更多参考资料。
Triplet模型支持一次输入3张图像,其中一张作为基准样本,另外两张作为正样本和负样本,通过约束正样本和基准样本的距离小于负样本和基准样本的距离,它可以让模型学习到在类内更加紧凑、类间更加分离的特征。
多任务模型
无论是使用分类模型,还是使用回归模型、排序模型,直接对通用的图像进行美学质量评估是非常困难的,因为不同风格的图像、不同语义特征的图像无法共用同样的评估标准。
所以一个好的图像美学质量评估模型,一定会根据不同的类别和语义信息来自适应学习美学特征,这是一个多任务学习过程。
多任务学习,即同时完成不同任务的学习,如在目标检测过程中的目标分类和定位,其中需要平衡不同任务的损失和学习速度。
监督信息
对于美学质量评估任务,可以使用额外任务,包括不同摄影风格的识别、不同语义内容的识别。
对于风格来说,它表征了一幅作品的主题和摄影手法,不同的摄影手法需要不同的评估标准。
对于语义来说,不同的内容所遵循的摄影准则有巨大的差异。例如,风景图常使用丰富的色调和三分法构图,而它们可能不适用于人像;人像和静物图则往往需要浅景深、干净的背景等。
模型
根据对输入、输出的使用方式不同,多任务学习有多种模型。在前面介绍的RAPID模型中,风格网络提取的特征与美学网络提取的特征一起作为网络的输入,BDN模型同样训练了多个风格子网络来预测图像的风格属性,这样的模型并没有多任务的损失,而是作为一种额外的监督信息用于优化学习过程。
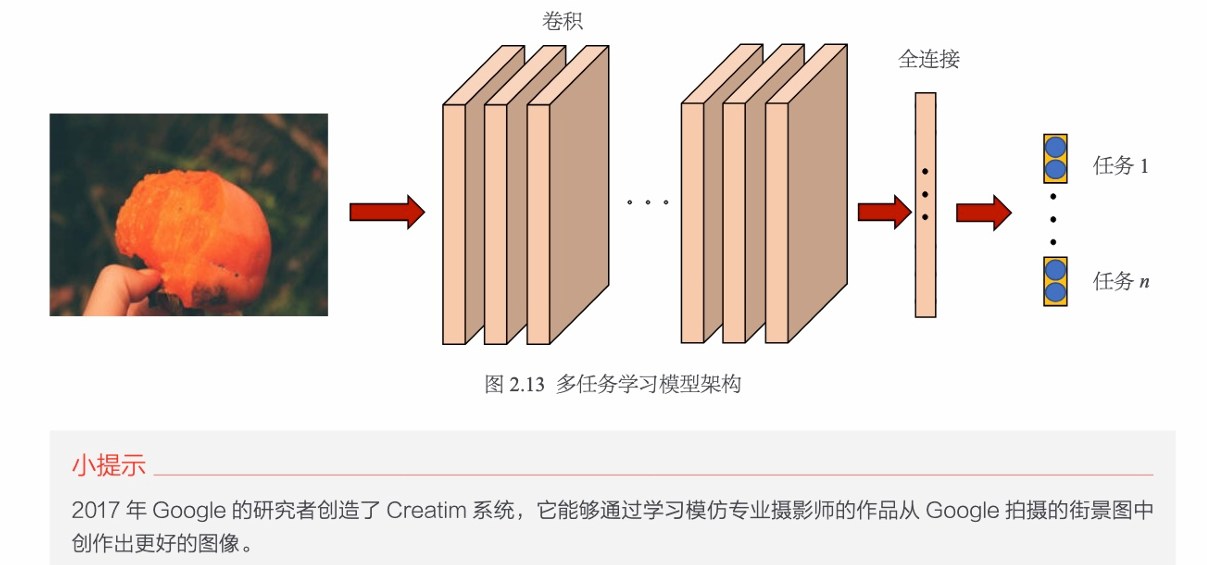
更多的多任务学习模型则将全连接层的输出分为多个任务,分别预测美学、风格、语义内容等,通过多任务损失的约束来进行学习,其架构如图2.13所示。
当前图像美学质量评估还面临着一些难题。
(1)美学的主观性决定了图像美学质量评估是一个非常具有挑战性的任务。到目前为止,在图像美学质量评估方面涌现了很多具有竞争力的模型,但是这个领域的研究状况还远未达到饱和。人工设计的美学特征很难被量化,也不够全面。虽然深度学习方法具有强大的自动特征学习能力,是现阶段图像美学质量评估的主流方法,但是如何学习适应各种风格的模型仍然是一个挑战。
(2)深度卷积神经网络输入图像在经过了裁剪、缩放或填充等操作,这会破坏图像原有的构图,从而损害图像的原始美感,如何同时保留图像的全局信息和局部信息是一个重要课题。
(3)将深度学习方法应用于图像美学质量评估面临的挑战还包括图像美学真值标签的模糊性和如何从有限的辅助信息中学习特定类别的图像美学特征。图像美学质量评估需要具有更丰富注释的、规模更大的数据集,其中每张图像最好由具有不同背景的、数量较多的用户标记。这样一个庞大而多样化的数据集将大大推动未来图像美学质量评估模型的发展。
(4)人的审美终究是有差异的,如何学习个性化的审美也是一个必须解决的问题。
- 感谢你赐予我前进的力量
-
微信
- 支付宝
