
模型部署系列(零)前置环境
本文最后更新于 2025-02-05,文章内容可能已经过时。
在这篇文章中我们会安装一些后续可能用到的工具。
CUDA
CUDA(Compute Unified Device Architecture,统一计算架构)是 NVIDIA 推出的一种并行计算平台和编程模型,用于利用 NVIDIA GPU(图形处理单元)进行高性能计算。CUDA 允许开发者使用标准的编程语言(如 C、C++、Python 等)编写程序,从而充分利用 GPU 的并行处理能力,显著加速计算密集型任务。
我们在这里需要知道如何在自己的平台上进行cuda版本的切换,从而适配不同的测试环境。
注意,我们使用GPU(特指英伟达)时会安装GPU的驱动(driver),而cuda的版本与driver存在对应关系,我们可以通过命令行查看:
nvidia-smi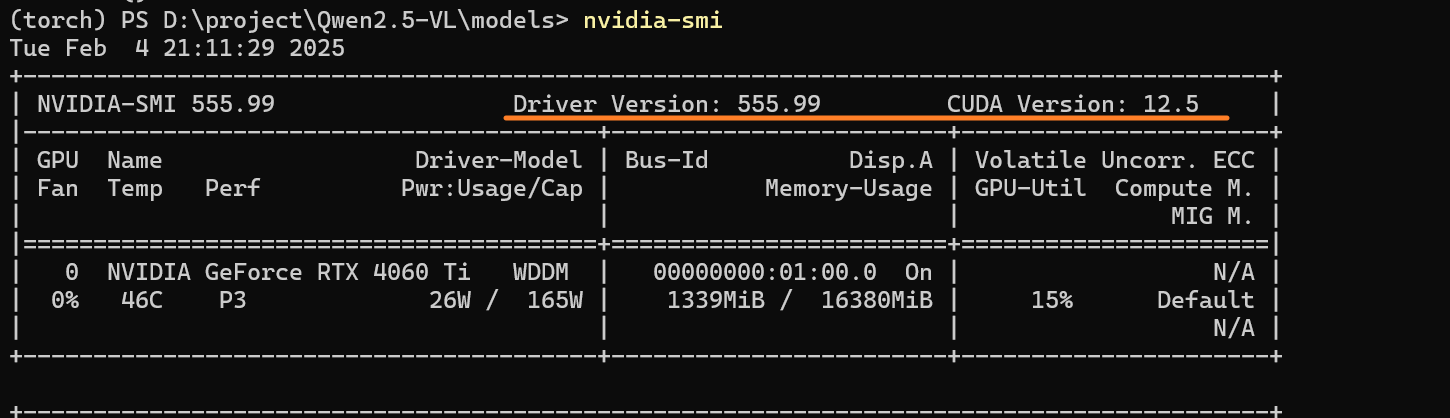
可以看见前部分是Driver的版本,后一部分则是该版本Driver所最高支持的CUDA。Driver的版本可以通过英伟达官方进行升级,但是一般我们不需要,因为CUDA的版本不需要太高。
我们可以通过命令行查看电脑是否存在CUDA:
nvcc -V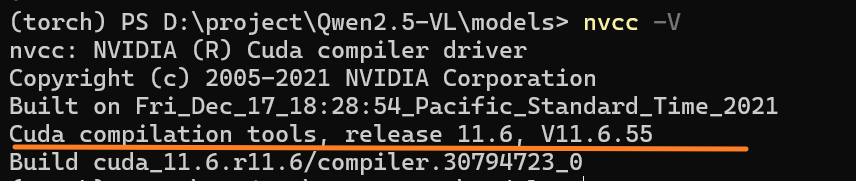
可以看到我已经安装了CUDA 11.6,但是这个版本不支持后续的某些工具,因此我需要下载更高版本的CUDA。
在Windows上切换CUDA
下载CUDA
在这个页面我们可以找到我们需要的CUDA版本,我自己考虑不要太新,因此安装CUDA 12.2.2
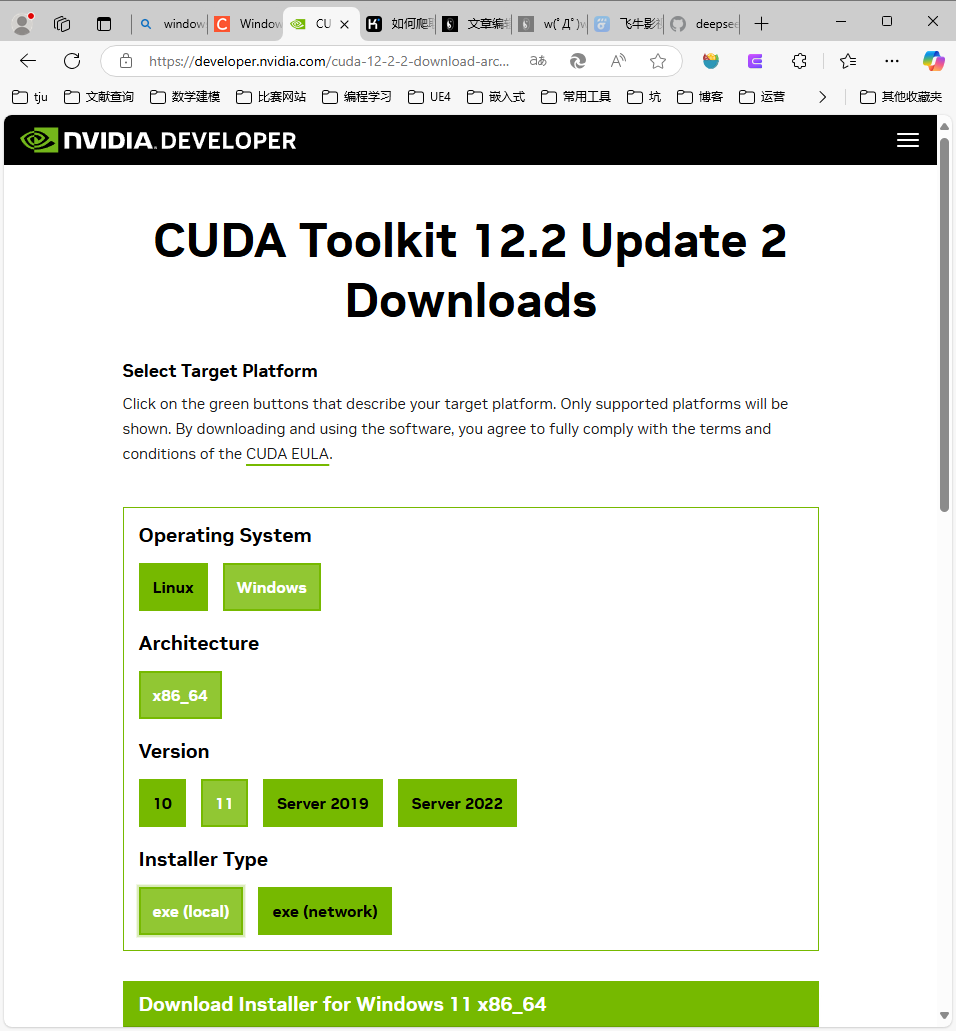
在该页面选择对应的选项即可
安装完成后我们需要配置环境变量切换版本
这一步可以参考其他博客
下载cudnn
下载后解压把以下文件复制到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.2
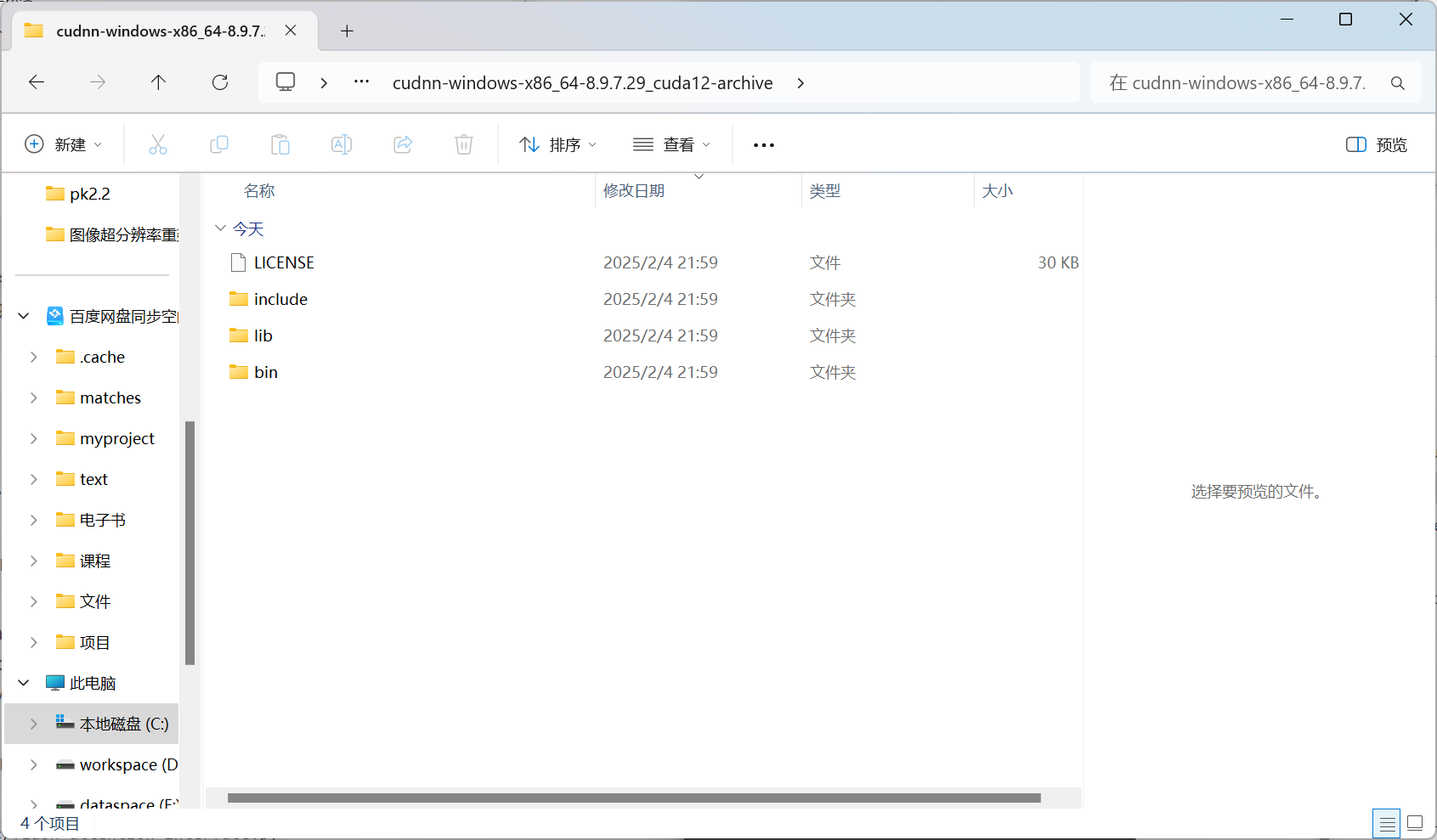
验证是否安装成功
复制完后,在当前目录下进入 extras -> demo_suite,可以看到有 bandwidthTest.exe 和 deviceQuery.exe
在该路径打开powershell
输入bandwidthTest.exe
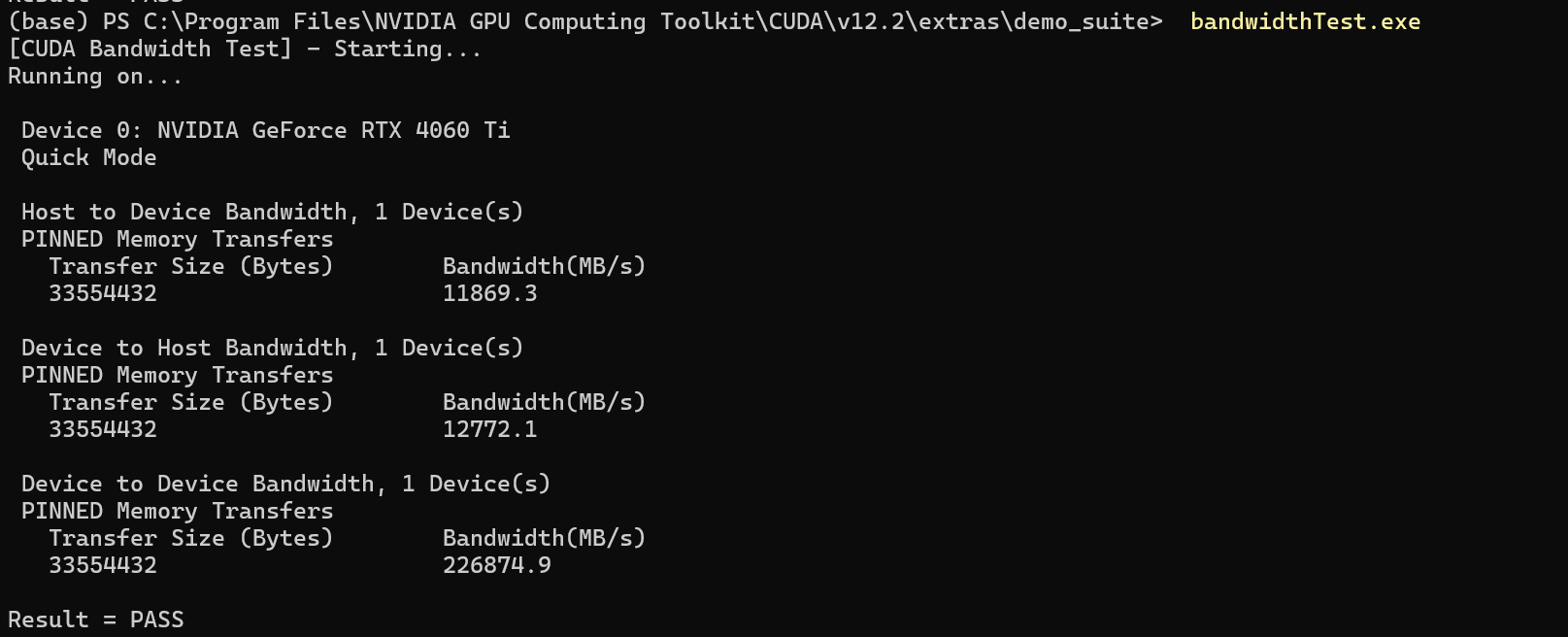
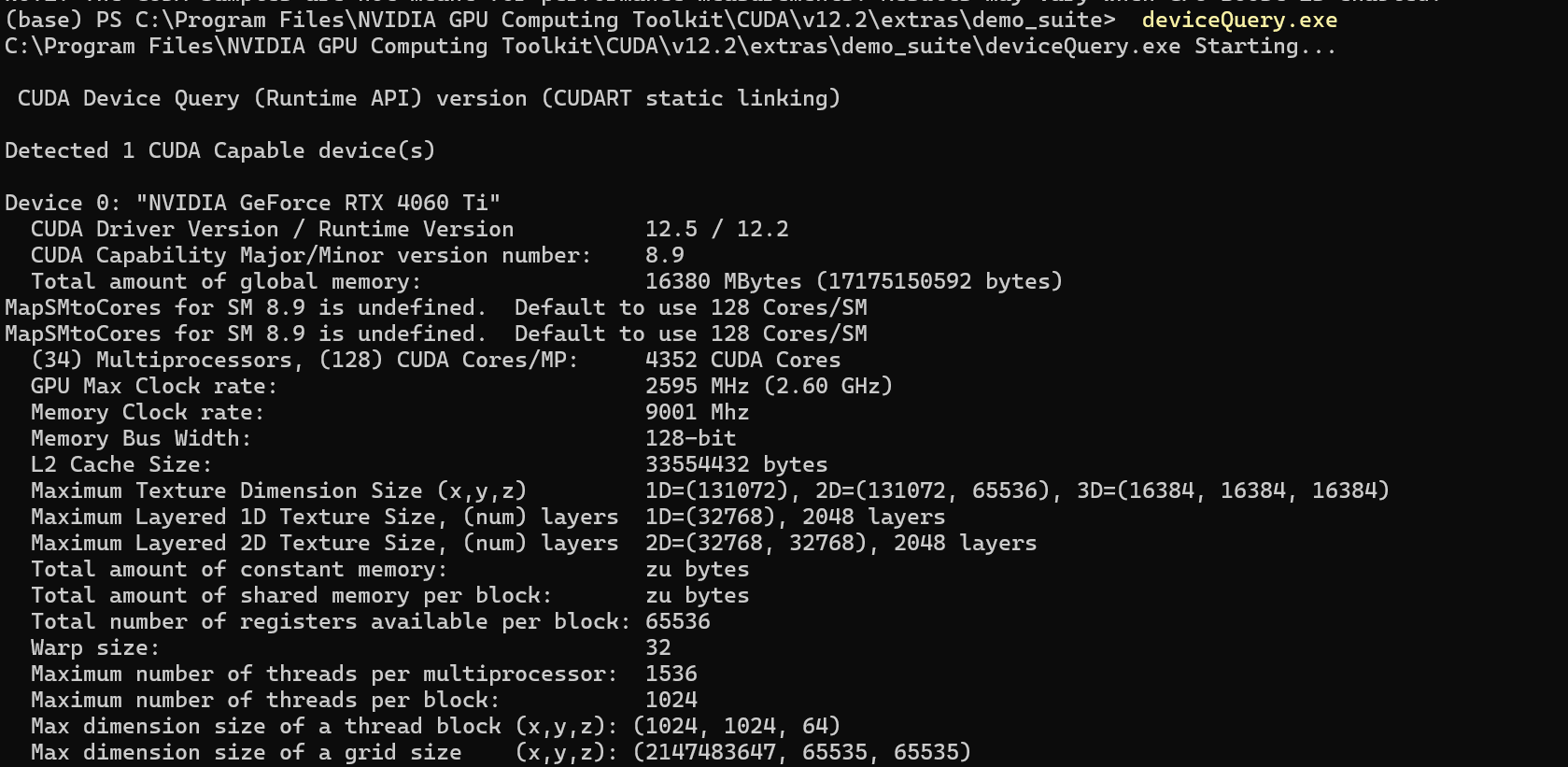
输入deviceQuery.exe
切换版本
安装完新版本的 CUDA 后,此时运行的环境为新版本的 CUDA,当我们需要切换为其他版本时,仅需要对环境变量进行修改即可
找到系统变量中Path
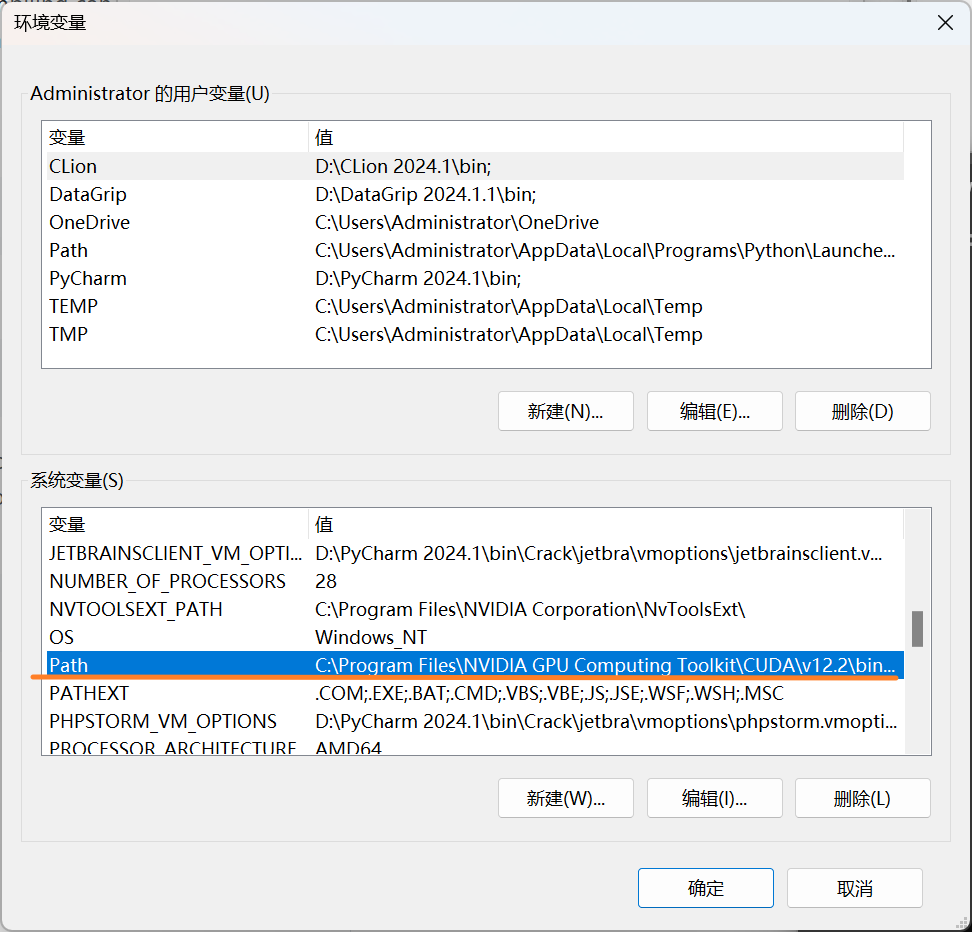
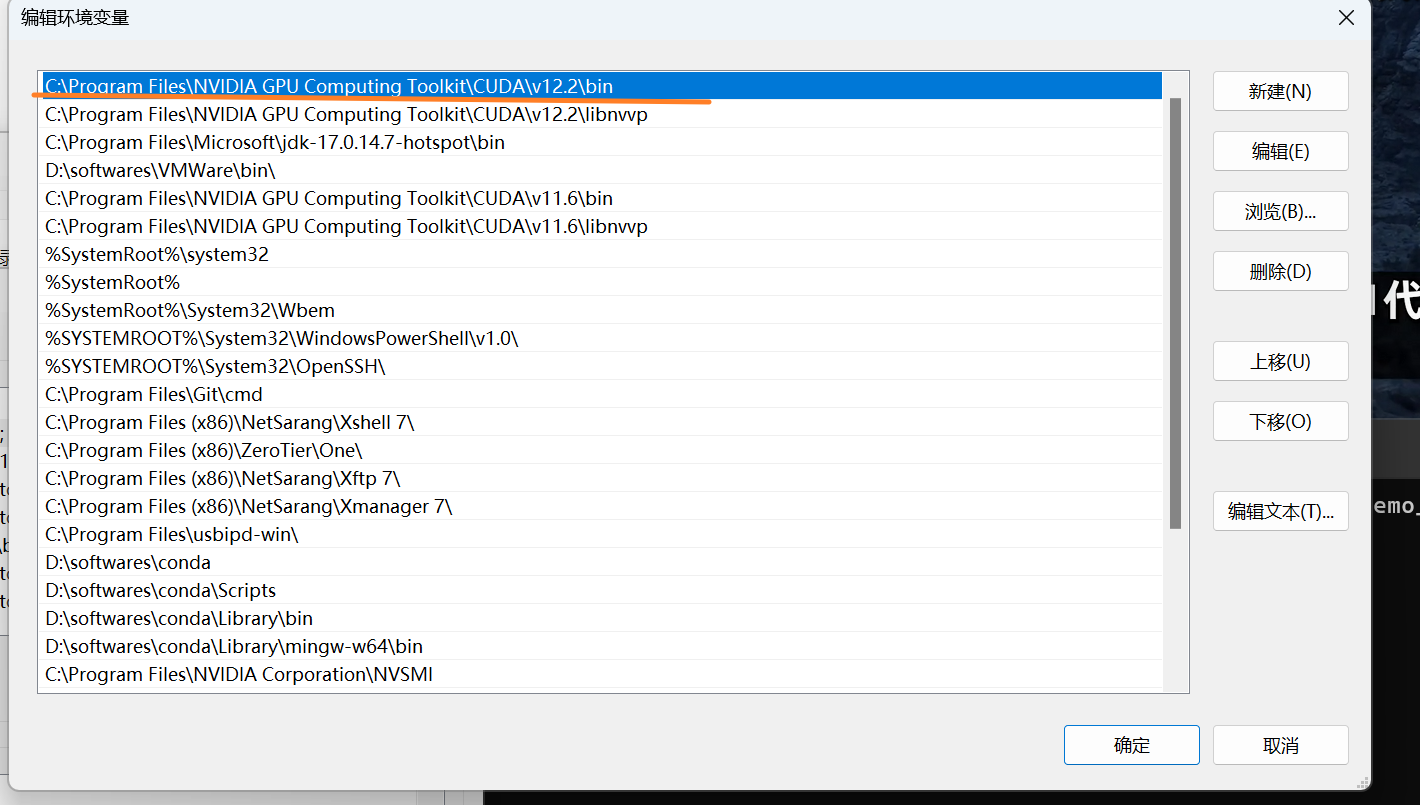
把对应版本移到最上方,并点击确定,如下图
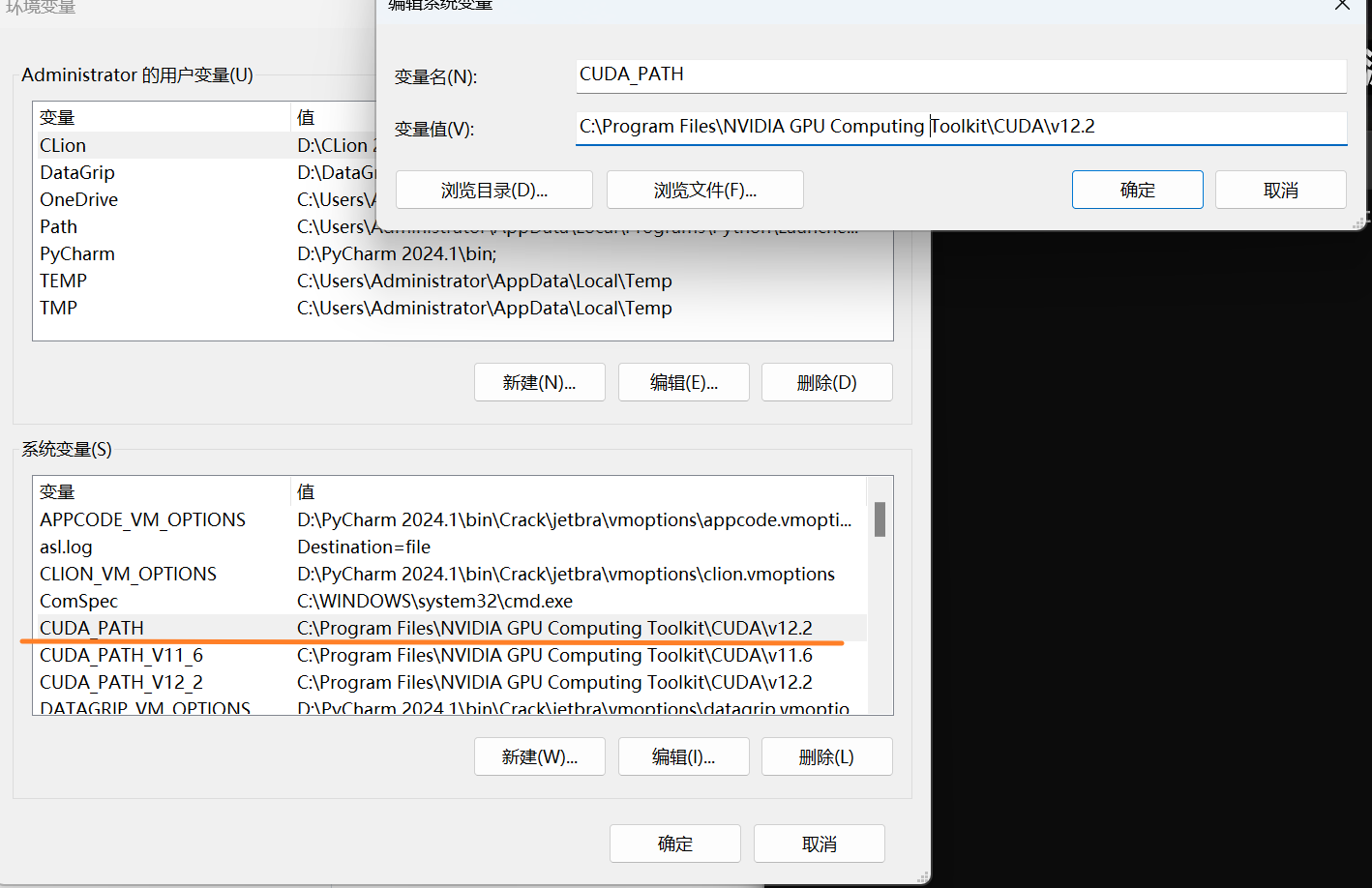
选中 CUDA_PATH ,点击 编辑
将值修改为 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.2
flash-attn
flash-attn 是一种优化注意力机制的高效计算库,主要用于加速基于 Transformer 的模型中的注意力计算,同时减少内存占用。它通过重新设计矩阵乘法操作,更好地适配现代硬件架构(如 GPU 的 Tensor Cores),从而显著提升模型的训练和推理性能。
核心功能
加速注意力计算:Flash Attention 通过优化内存访问模式和减少冗余计算,显著提高了注意力机制的计算速度。
减少内存占用:通过分块计算和缓存优化,减少了对高带宽内存(HBM)的依赖,从而降低了内存占用。
支持多种注意力模式:包括因果注意力(Causal Attention)、滑动窗口局部注意力(Sliding Window Local Attention)以及多查询注意力(MQA)和分组查询注意力(GQA)。
兼容性:Flash Attention 已集成到 PyTorch 2.0 中,可以方便地调用。
pip install flash-attn直接pip安装无法安装flash-attn2
指定版本flash-aatn安装
我的Python版本是3.11,因此找到如下版本(注意如果版本不匹配,需要重装torch/cuda来确保版本匹配):
以下重装torch
pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 -f https://mirrors.aliyun.com/pytorch-wheels/cu124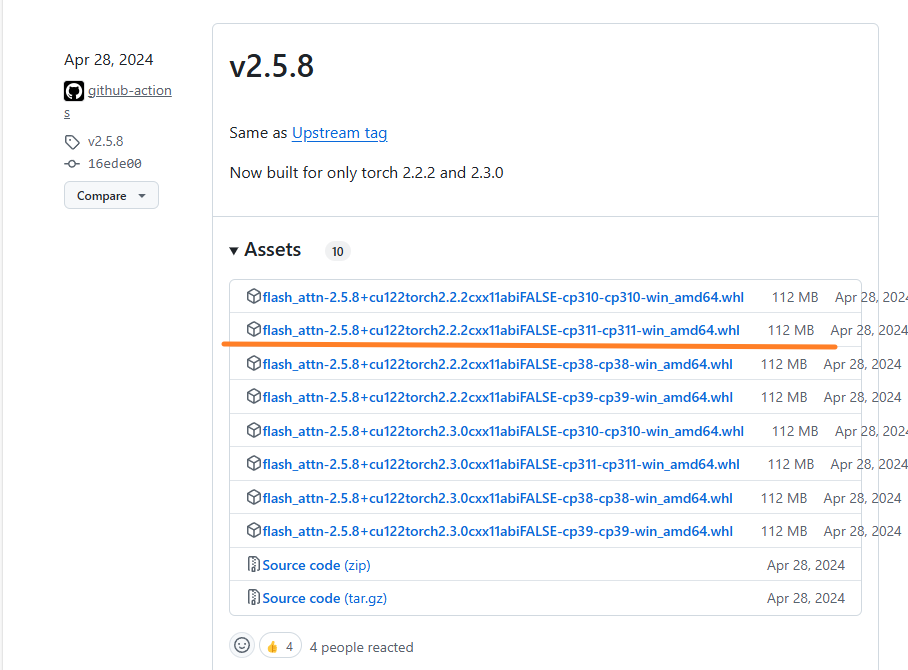
下载后安装:
pip install flash_attn-2.6.3+cu123torch2.2.2cxx11abiFALSE-cp311-cp311-win_amd64.whl安装完成后可以使用以下代码进行测试:
import torch
from flash_attn import flash_attn_func
# 检查 CUDA 是否可用
if not torch.cuda.is_available():
raise RuntimeError("CUDA is not available. Please check your PyTorch installation.")
# 设置设备
device = torch.device("cuda")
# 创建随机输入张量
batch_size = 2
seq_len = 128
num_heads = 8
head_dim = 64
query = torch.randn(batch_size, seq_len, num_heads, head_dim, device=device, dtype=torch.float16)
key = torch.randn(batch_size, seq_len, num_heads, head_dim, device=device, dtype=torch.float16)
value = torch.randn(batch_size, seq_len, num_heads, head_dim, device=device, dtype=torch.float16)
# 调用 Flash-Attn2
output = flash_attn_func(query, key, value, causal=False)
print("Output shape:", output.shape)
Triton
Triton 是一个由 OpenAI 开发的编程语言和编译器,专门用于编写高性能的 GPU 内核。它的目标是简化 GPU 编程,提供比 CUDA 更高的生产力,同时保持接近或超过手写 CUDA 代码的性能。Triton 采用基于分块的编程范式,允许开发者在更高的抽象层次上编写代码,而编译器则负责处理底层的优化。
环境要求
torch >= 2.4.0;CUDA >=12;安装
MSVC和Windows SDK;环境需要有
msvcp140.dll和vcruntime140.dll。如果然后就可以安装他编译的 whl,实现真正的功能。
安装MSVC 和 Windows SDK
此处略过
添加环境变量
请参考该博客完成环境变量添加
安装Triton-Win
以上工作完成后下载对应的whl:triton-windows
pip install flash_attn-2.7.1.post1+cu124torch2.5.1cxx11abiFALSE-cp311-cp311-win_amd64.whl验证安装
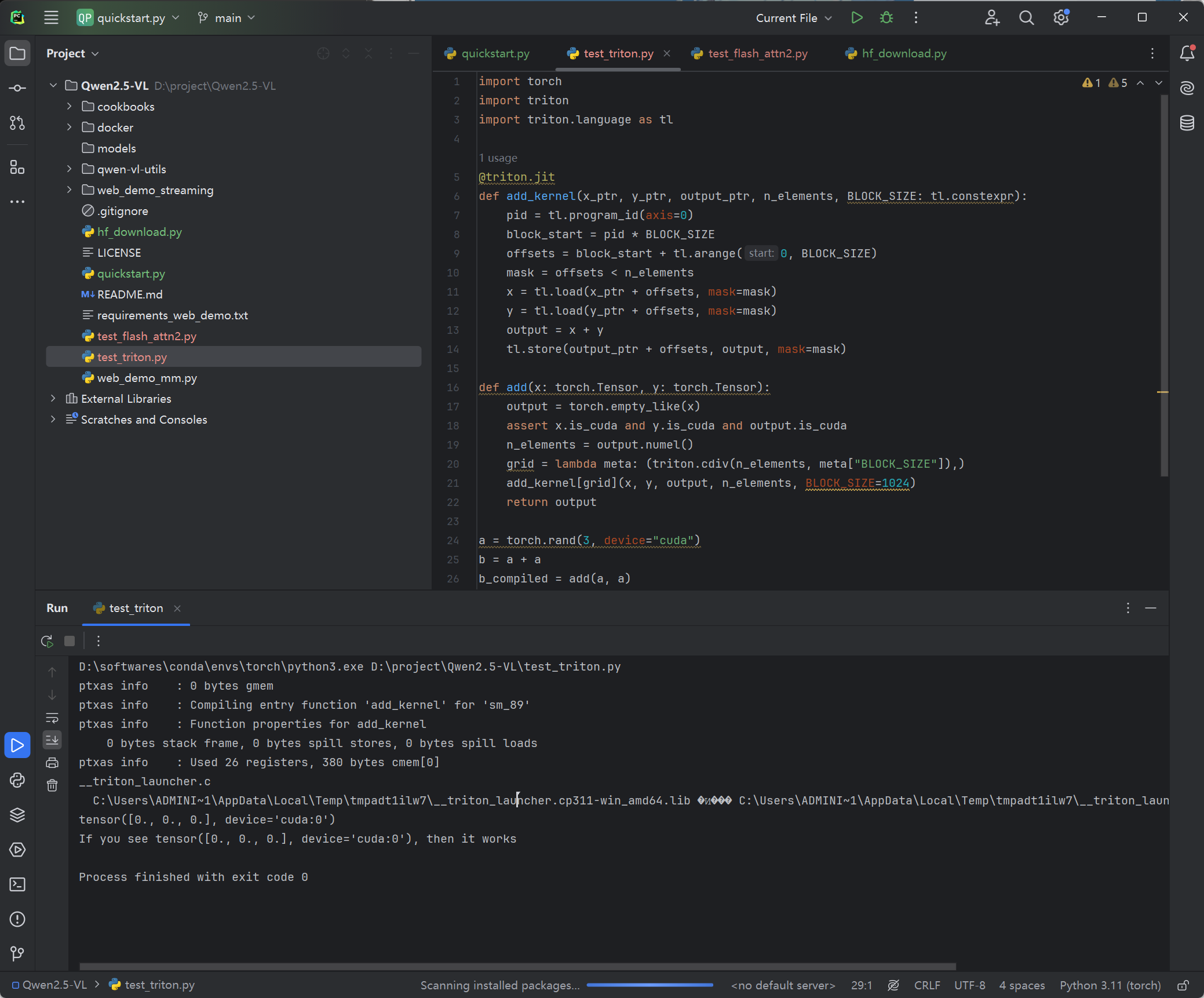
添加test_triton.py
import torch
import triton
import triton.language as tl
@triton.jit
def add_kernel(x_ptr, y_ptr, output_ptr, n_elements, BLOCK_SIZE: tl.constexpr):
pid = tl.program_id(axis=0)
block_start = pid * BLOCK_SIZE
offsets = block_start + tl.arange(0, BLOCK_SIZE)
mask = offsets < n_elements
x = tl.load(x_ptr + offsets, mask=mask)
y = tl.load(y_ptr + offsets, mask=mask)
output = x + y
tl.store(output_ptr + offsets, output, mask=mask)
def add(x: torch.Tensor, y: torch.Tensor):
output = torch.empty_like(x)
assert x.is_cuda and y.is_cuda and output.is_cuda
n_elements = output.numel()
grid = lambda meta: (triton.cdiv(n_elements, meta["BLOCK_SIZE"]),)
add_kernel[grid](x, y, output, n_elements, BLOCK_SIZE=1024)
return output
a = torch.rand(3, device="cuda")
b = a + a
b_compiled = add(a, a)
print(b_compiled - b)
print("If you see tensor([0., 0., 0.], device='cuda:0'), then it works")
- 感谢你赐予我前进的力量
-
微信
- 支付宝