
动手学深度学习v2(4.8)数值稳定性和模型初始化
本文最后更新于 2024-11-18,文章内容可能已经过时。
到目前为止,我们实现的每个模型都是根据某个预先指定的分布来初始化模型的参数。 有人会认为初始化方案是理所当然的,忽略了如何做出这些选择的细节。甚至有人可能会觉得,初始化方案的选择并不是特别重要。 相反,初始化方案的选择在神经网络学习中起着举足轻重的作用, 它对保持数值稳定性至关重要。 此外,这些初始化方案的选择可以与非线性激活函数的选择有趣的结合在一起。 我们选择哪个函数以及如何初始化参数可以决定优化算法收敛的速度有多快。 糟糕选择可能会导致我们在训练时遇到梯度爆炸或梯度消失。 本节将更详细地探讨这些主题,并讨论一些有用的启发式方法。 这些启发式方法在整个深度学习生涯中都很有用。
梯度消失和梯度爆炸

不稳定梯度带来的风险不止在于数值表示; 不稳定梯度也威胁到我们优化算法的稳定性。 我们可能面临一些问题。 要么是梯度爆炸(gradient exploding)问题: 参数更新过大,破坏了模型的稳定收敛; 要么是梯度消失(gradient vanishing)问题: 参数更新过小,在每次更新时几乎不会移动,导致模型无法学习。
梯度消失
曾经sigmoid函数\frac{1}{(1+exp(−x))}( 4.1节提到过)很流行, 因为它类似于阈值函数。 由于早期的人工神经网络受到生物神经网络的启发, 神经元要么完全激活要么完全不激活(就像生物神经元)的想法很有吸引力。 然而,它却是导致梯度消失问题的一个常见的原因, 让我们仔细看看sigmoid函数为什么会导致梯度消失。
%matplotlib inline
import torch
from d2l import torch as d2l
x = torch.arange(-8.0, 8.0, 0.1, requires_grad=True)
y = torch.sigmoid(x)
y.backward(torch.ones_like(x))
d2l.plot(x.detach().numpy(), [y.detach().numpy(), x.grad.numpy()],
legend=['sigmoid', 'gradient'], figsize=(4.5, 2.5))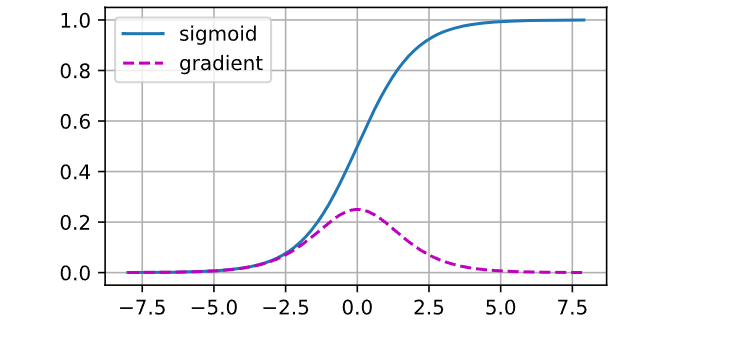
正如上图,当sigmoid函数的输入很大或是很小时,它的梯度都会消失。 此外,当反向传播通过许多层时,除非我们在刚刚好的地方, 这些地方sigmoid函数的输入接近于零,否则整个乘积的梯度可能会消失。 当我们的网络有很多层时,除非我们很小心,否则在某一层可能会切断梯度。 事实上,这个问题曾经困扰着深度网络的训练。 因此,更稳定的ReLU系列函数已经成为从业者的默认选择(虽然在神经科学的角度看起来不太合理)。

梯度爆炸
相反,梯度爆炸可能同样令人烦恼。 为了更好地说明这一点,我们生成100个高斯随机矩阵,并将它们与某个初始矩阵相乘。 对于我们选择的尺度(方差σ^2=1),矩阵乘积发生爆炸。 当这种情况是由于深度网络的初始化所导致时,我们没有机会让梯度下降优化器收敛。
M = torch.normal(0, 1, size=(4,4))
print('一个矩阵 \n',M)
for i in range(100):
M = torch.mm(M,torch.normal(0, 1, size=(4, 4)))
print('乘以100个矩阵后\n', M)
让训练更加稳定


通过约束梯度方差使得每一层梯度落在非饱和区(如sigmoid),避免梯度消失和爆炸。
打破对称性

参数初始化
解决(或至少减轻)上述问题的一种方法是进行参数初始化, 优化期间的注意和适当的正则化也可以进一步提高稳定性。

默认初始化
在前面的部分中,例如在 3.3节中, 我们使用正态分布来初始化权重值。如果我们不指定初始化方法, 框架将使用默认的随机初始化方法,对于中等难度的问题,这种方法通常很有效。

Xavier初始化




额外阅读
上面的推理仅仅触及了现代参数初始化方法的皮毛。 深度学习框架通常实现十几种不同的启发式方法。 此外,参数初始化一直是深度学习基础研究的热点领域。 其中包括专门用于参数绑定(共享)、超分辨率、序列模型和其他情况的启发式算法。 例如,Xiao等人演示了通过使用精心设计的初始化方法 (Xiao et al., 2018), 可以无须架构上的技巧而训练10000层神经网络的可能性。
如果有读者对该主题感兴趣,我们建议深入研究本模块的内容, 阅读提出并分析每种启发式方法的论文,然后探索有关该主题的最新出版物。 也许会偶然发现甚至发明一个聪明的想法,并为深度学习框架提供一个实现。
小结
梯度消失和梯度爆炸是深度网络中常见的问题。在参数初始化时需要非常小心,以确保梯度和参数可以得到很好的控制。
需要用启发式的初始化方法来确保初始梯度既不太大也不太小。
ReLU激活函数缓解了梯度消失问题,这样可以加速收敛。
随机初始化是保证在进行优化前打破对称性的关键。
Xavier初始化表明,对于每一层,输出的方差不受输入数量的影响,任何梯度的方差不受输出数量的影响。
练习
1.除了多层感知机的排列对称性之外,还能设计出其他神经网络可能会表现出对称性且需要被打破的情况吗?
2.我们是否可以将线性回归或softmax回归中的所有权重参数初始化为相同的值?
3.在相关资料中查找两个矩阵乘积特征值的解析界。这对确保梯度条件合适有什么启示?
4.如果我们知道某些项是发散的,我们能在事后修正吗?看看关于按层自适应速率缩放的论文 (You et al., 2017) 。
- 感谢你赐予我前进的力量
-
微信
- 支付宝