
动手学深度学习v2(4.7)前向传播、反向传播和计算图
本文最后更新于 2024-11-17,文章内容可能已经过时。
我们已经学习了如何用小批量随机梯度下降训练模型。 然而当实现该算法时,我们只考虑了通过前向传播(forward propagation)所涉及的计算。 在计算梯度时,我们只调用了深度学习框架提供的反向传播函数,而不知其所以然。
梯度的自动计算(自动微分)大大简化了深度学习算法的实现。 在自动微分之前,即使是对复杂模型的微小调整也需要手工重新计算复杂的导数, 学术论文也不得不分配大量页面来推导更新规则。 本节将通过一些基本的数学和计算图, 深入探讨反向传播的细节。 首先,我们将重点放在带权重衰减(L2正则化)的单隐藏层多层感知机上。
前向传播
前向传播(forward propagation或forward pass) 指的是:按顺序(从输入层到输出层)计算和存储神经网络中每层的结果。

前向传播计算图
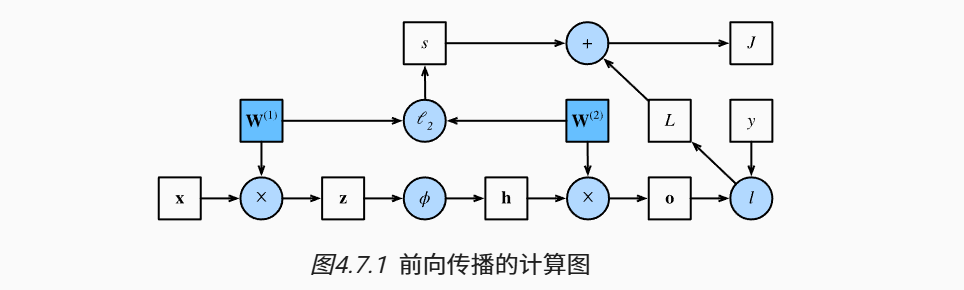
绘制计算图有助于我们可视化计算中操作符和变量的依赖关系。 图4.7.1 是与上述简单网络相对应的计算图, 其中正方形表示变量,圆圈表示操作符。 左下角表示输入,右上角表示输出。 注意显示数据流的箭头方向主要是向右和向上的。
反向传播


训练神经网络
在训练神经网络时,前向传播和反向传播相互依赖。 对于前向传播,我们沿着依赖的方向遍历计算图并计算其路径上的所有变量。 然后将这些用于反向传播,其中计算顺序与计算图的相反。

因此,在训练神经网络时,在初始化模型参数后, 我们交替使用前向传播和反向传播,利用反向传播给出的梯度来更新模型参数。 注意,反向传播重复利用前向传播中存储的中间值,以避免重复计算。 带来的影响之一是我们需要保留中间值,直到反向传播完成。 这也是训练比单纯的预测需要更多的内存(显存)的原因之一。 此外,这些中间值的大小与网络层的数量和批量的大小大致成正比。 因此,使用更大的批量来训练更深层次的网络更容易导致内存不足(out of memory)错误。
小结
前向传播在神经网络定义的计算图中按顺序计算和存储中间变量,它的顺序是从输入层到输出层。
反向传播按相反的顺序(从输出层到输入层)计算和存储神经网络的中间变量和参数的梯度。
在训练深度学习模型时,前向传播和反向传播是相互依赖的。
训练比预测需要更多的内存。
练习

- 感谢你赐予我前进的力量
-
微信
- 支付宝