
Kaggle竞赛动手系列(一)Forecasting Sticker Sales
本文最后更新于 2025-01-25,文章内容可能已经过时。
下载并读取数据
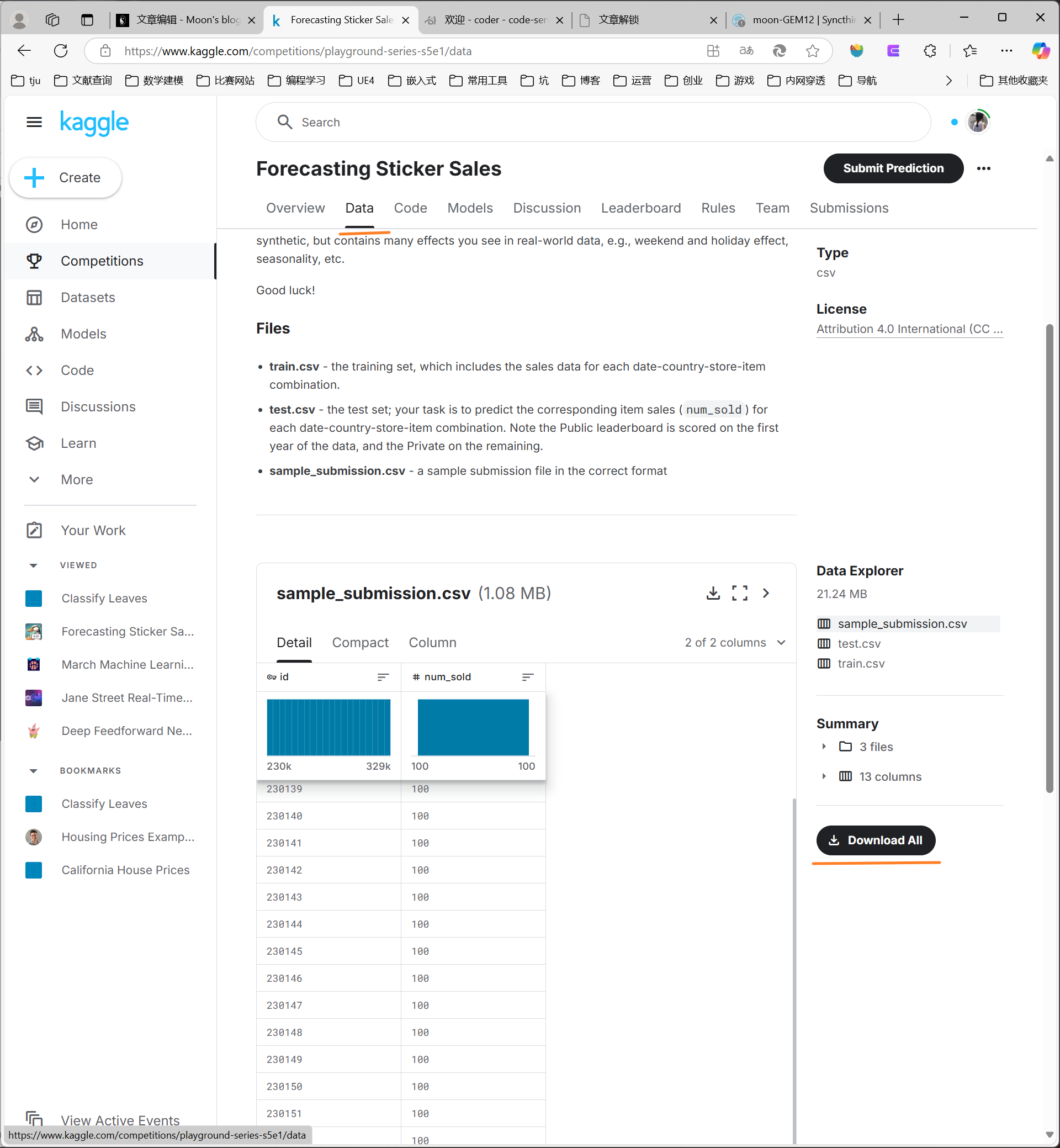
在data栏下载所有数据上传到Jupyter中,接下来我们开始读取数据
# 读取CSV文件
df_train = pd.read_csv('./data/train.csv')
df_test = pd.read_csv('./data/test.csv')
# 查看数据
print(df_train)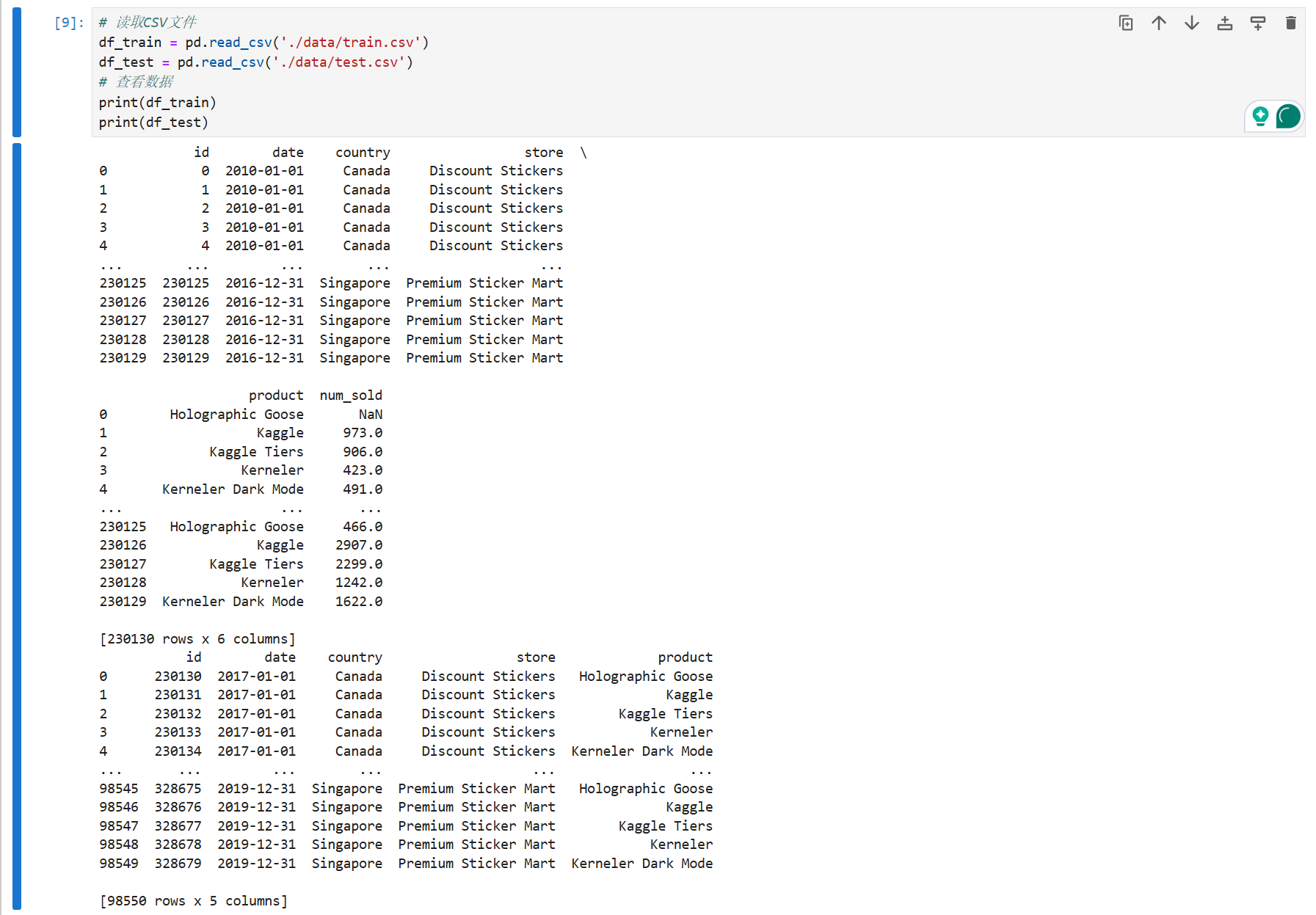
可以看见,训练集和测试集在特征维度是一致的,测试集与训练集的差异就在我们需要预测的标签——num_sold ,这意味着我们基本上不需要对特征进行诸如PCA的处理。
预处理
处理缺失值
我们来查看一下缺失值情况
train_nan_positions = df_train.isna()
print(train_nan_positions)
train_nan_count_per_column = df_train.isna().sum()
print(train_nan_count_per_column)
test_nan_positions = df_test.isna()
print(test_nan_positions)
test_nan_count_per_column = df_test.isna().sum()
print(test_nan_count_per_column)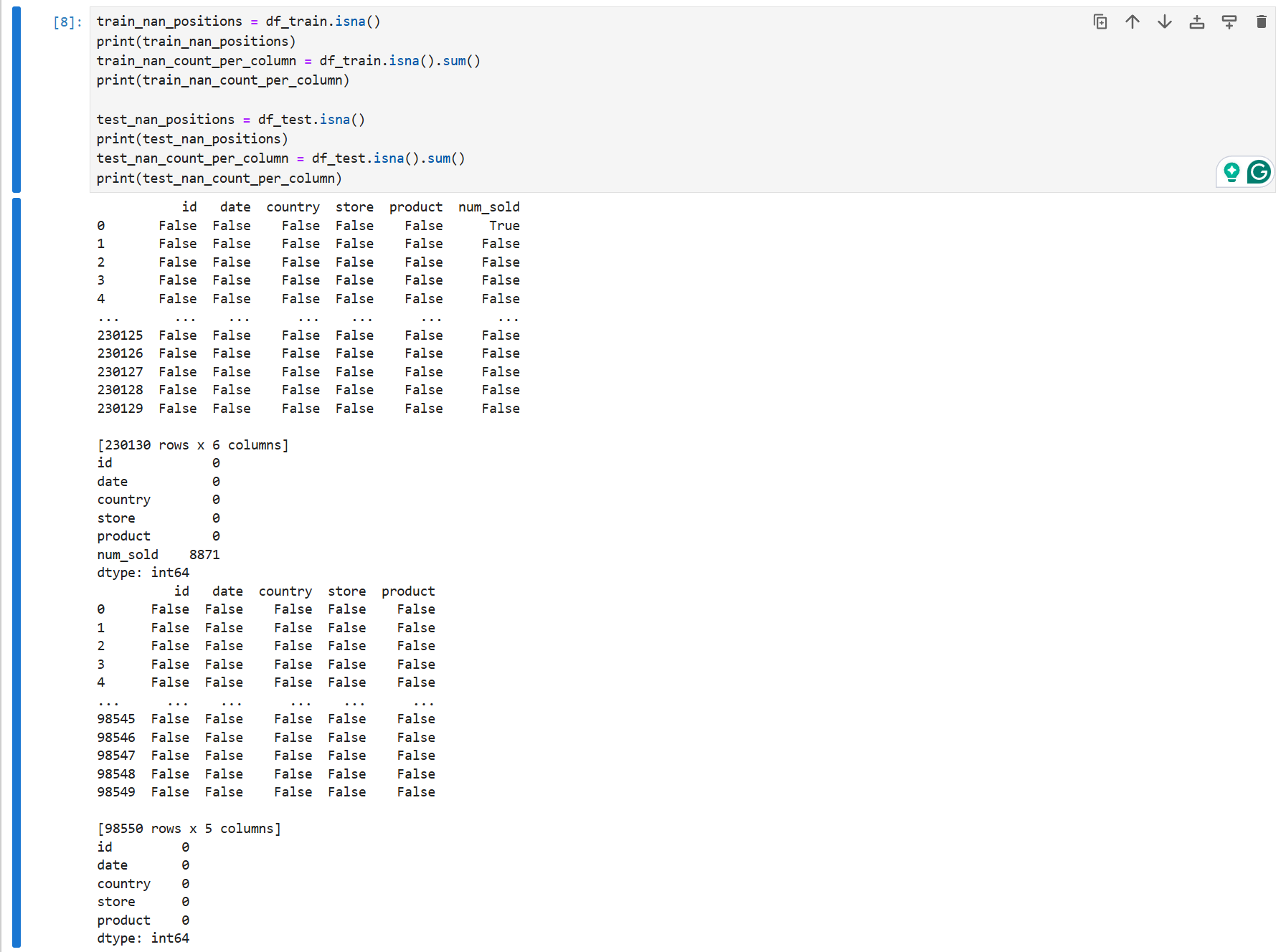
可以看见缺失值仅在训练集中的num_sold 中。结合实际情况与数据集大小,缺少的8871条数据在230130条中可以忽略不计,因此考虑直接删除
df_train_clean_na = df_train.dropna(axis=0, how='any')
train_nan_positions = df_train_clean_na.isna()
print(train_nan_positions)
train_nan_count_per_column = df_train_clean_na.isna().sum()
print(train_nan_count_per_column)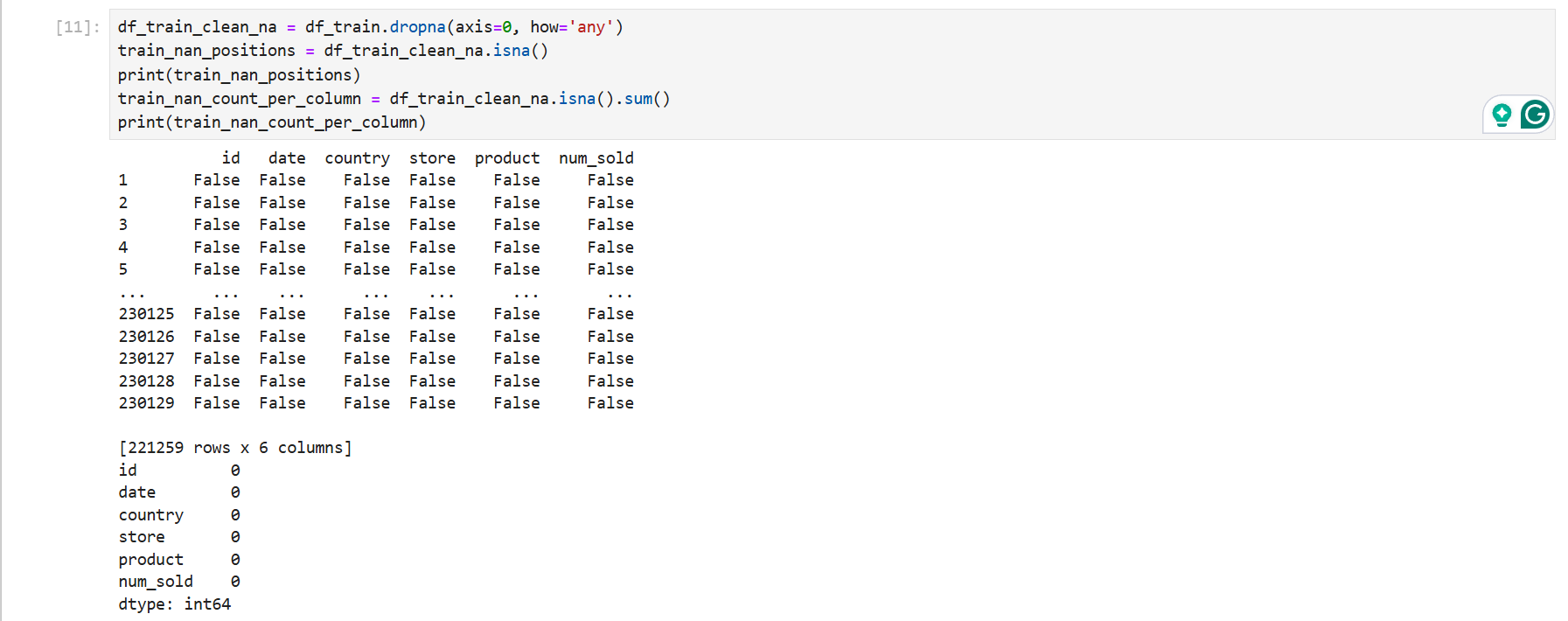
可以看见我们已经删除了缺失行。
时间型变量编码
首先id与num_sold是没有关系的,而其他的特征都不是数值型,因此我们需要对其他的变量进行编码,这样才能方便我们后面的统计与处理
对于时间型变量的处理我们可以使用pandas进行提取:
df_train_clean_na['date'] = pd.to_datetime(df_train_clean_na['date'])
print(df_train_clean_na)
df_test['date'] = pd.to_datetime(df_test['date'])
print(df_test)
为了确认label是否与时间有关系,我们绘制一下直方图:
plt.plot(df_train_clean_na['date'],df_train_clean_na['num_sold'])
plt.legend()
plt.xlabel('Time')
plt.ylabel('Value')
plt.show()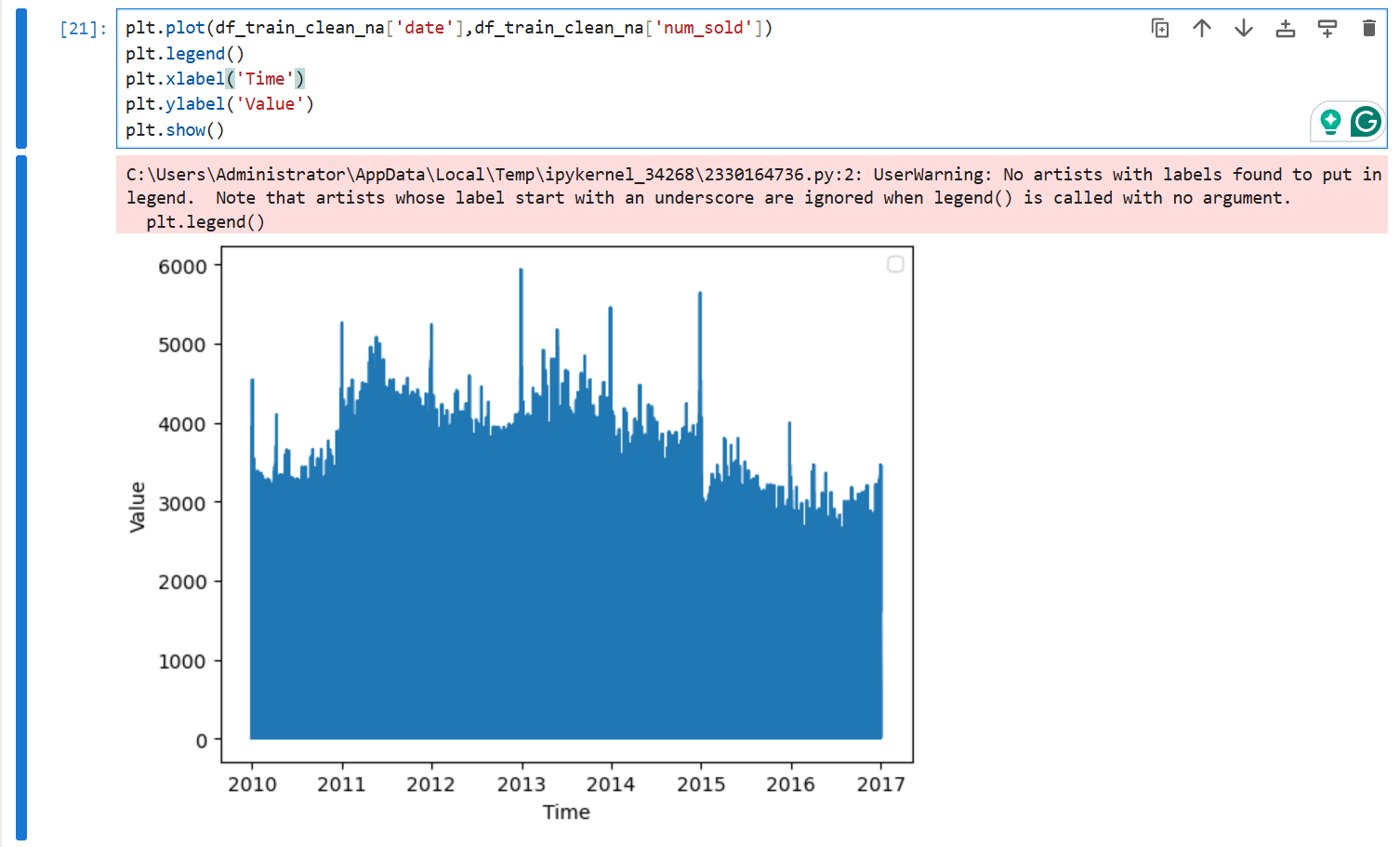
可以比较明显地看出label与Time是有一定时间周期性的关系,因此我们需要将时间也作为特征提取,我们将时间按照年、月、日拆开,这样可以作为数值型特征,同时删除不需要的id和date特征:
df_train_clean_na['year'] = df_train_clean_na['date'].dt.year.astype(int)
df_train_clean_na['month'] = df_train_clean_na['date'].dt.month.astype(int)
df_train_clean_na['day'] = df_train_clean_na['date'].dt.day.astype(int)
df_train_clean_na.drop(columns=['id', 'date'], inplace=True)
print(df_train_clean_na)
df_test['year'] = df_test['date'].dt.year.astype(int)
df_test['month'] = df_test['date'].dt.month.astype(int)
df_test['day'] = df_test['date'].dt.day.astype(int)
df_test.drop(columns=['id', 'date'], inplace=True)
print(df_test)
字符型变量编码
随后我们需要对其他几列进行编码,由于这几项不具备顺序关系,因此我们采用one-hot编码:
df_train_encoded = pd.get_dummies(df_train_clean_na, columns=['country','store','product']).astype(int)
print(df_train_encoded)
print(df_train_encoded.columns)
df_test_encoded = pd.get_dummies(df_test, columns=['country','store','product']).astype(int)
print(df_test_encoded)
print(df_test_encoded.columns)
可以看到已经全部为数值类型,现在我们可以看一下数据的统计信息:
print(df_train_encoded.describe())
print(df_test_encoded.describe())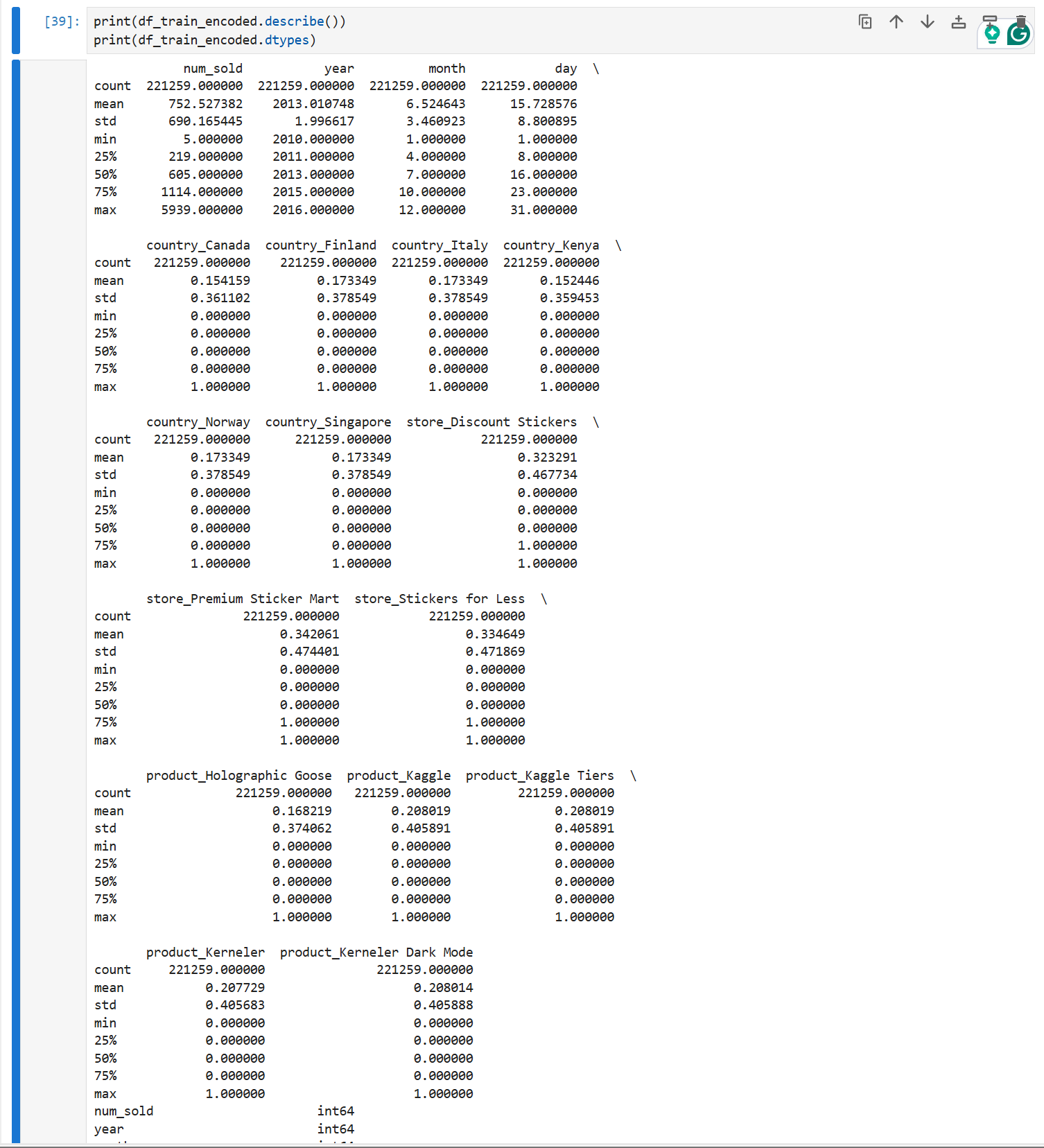
接下来我们查看测试集的统计信息
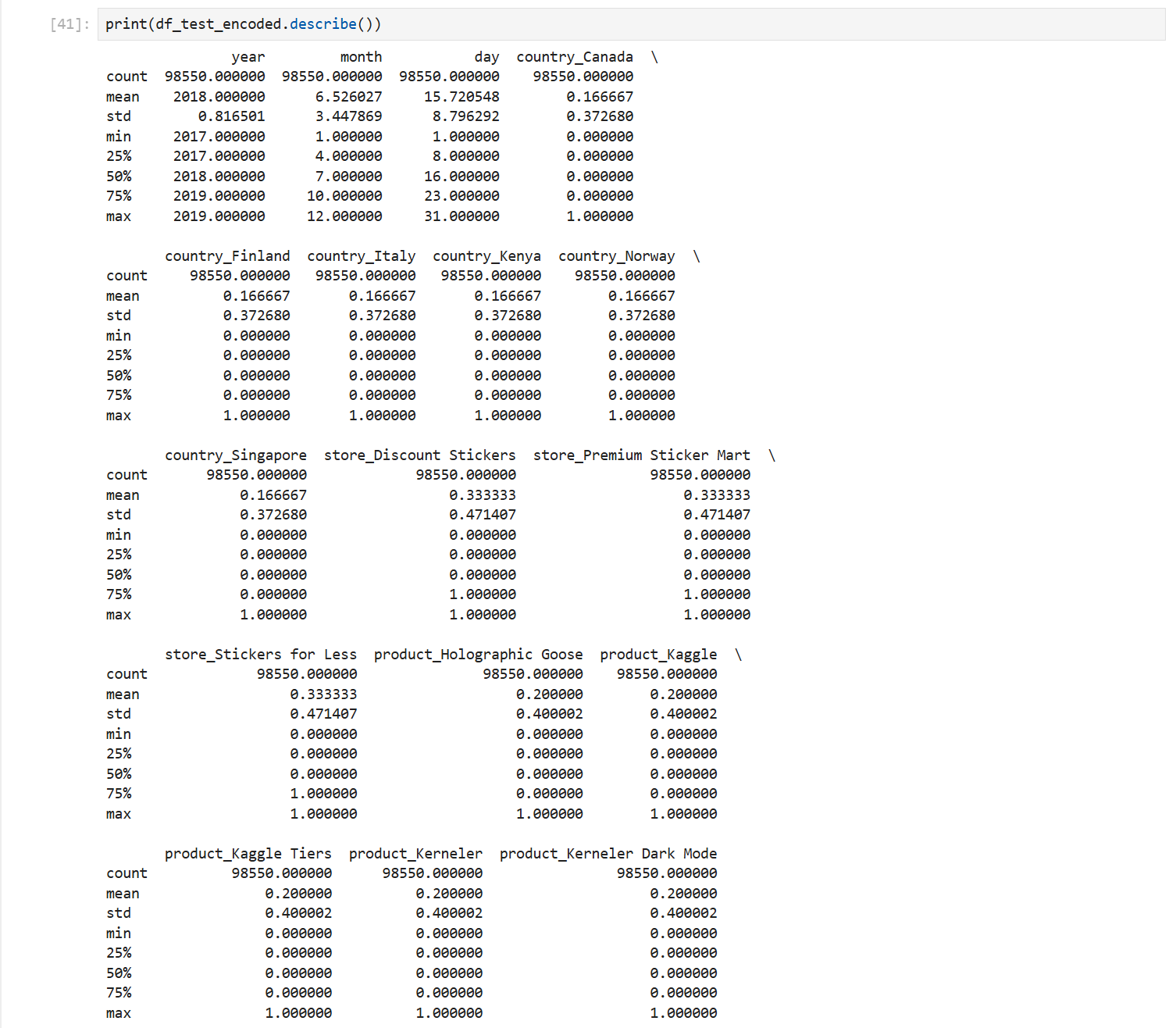
从测试集的统计信息可以明显看出这是一个通过构造分布得到的测试集。
归一化
为了后续模型收敛更快,我们对数据进行归一化操作,注意labels在这一步我们要单独提出来:
scaler = MinMaxScaler()
labels = df_train_encoded['num_sold']
df_train_encoded = df_train_encoded.iloc[:,1:]
df_train_standardized = pd.DataFrame(scaler.fit_transform(df_train_encoded), columns=df_train_encoded.columns)
df_test_standardized = pd.DataFrame(scaler.fit_transform(df_test_encoded), columns=df_test_encoded.columns)
print(labels)
print(df_train_standardized)
print(df_test_standardized)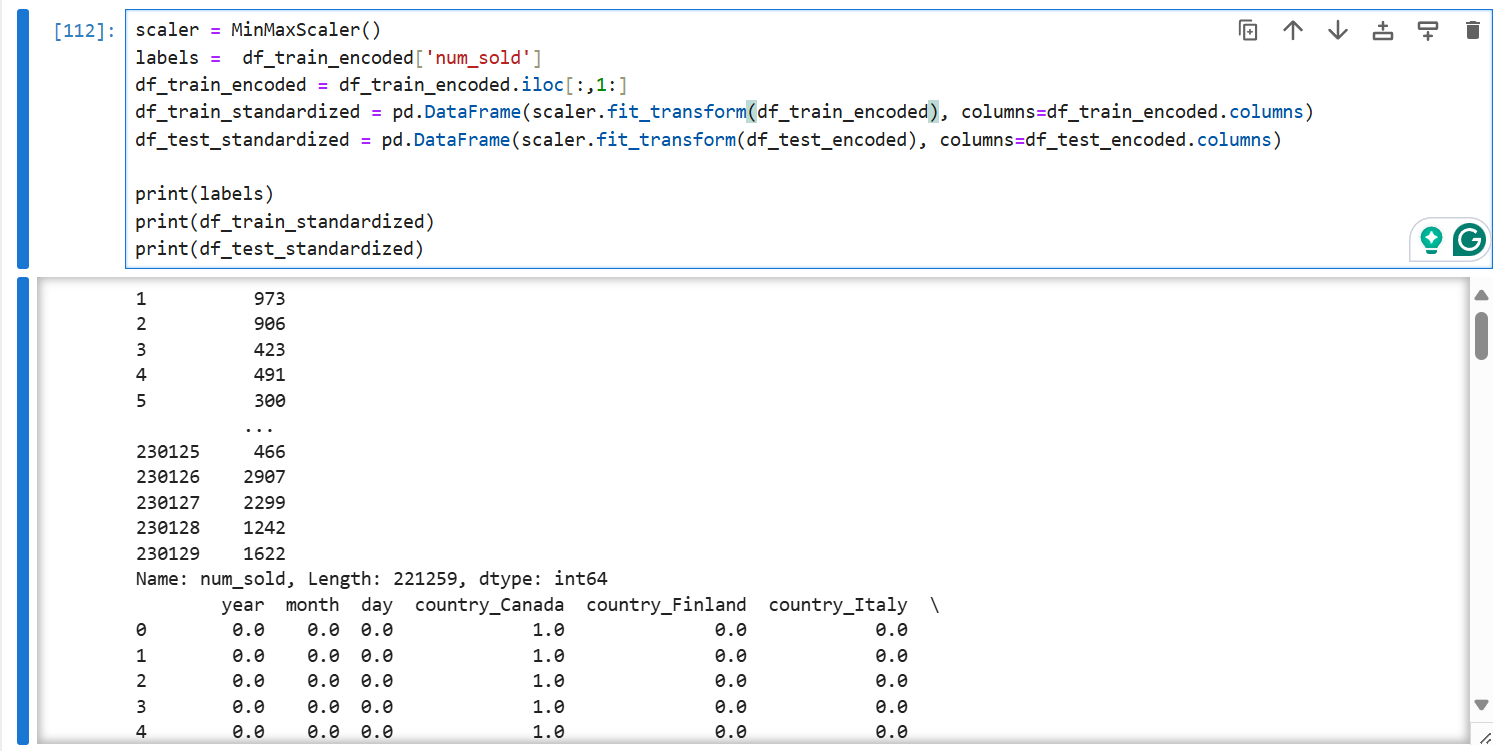
转换为tensor
为后续训练,我们需要将数据转换为tensor
train_data = torch.tensor(df_train_standardized.values, dtype=torch.float32)
test_data = torch.tensor(df_test_standardized.values, dtype=torch.float32)
train_labels = torch.tensor(
labels.values.reshape(-1, 1), dtype=torch.float32)
print(train_data)
print(test_data)
print(train_labels)回归模型
注意在回归时,计算模型的Loss应该使用mape。
线性回归
from sklearn.linear_model import LinearRegressionX_train, X_vali, y_train, y_vali = train_test_split(train_data, train_labels, test_size = 0.2, random_state=42)
model = LinearRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_vali)
mape = mean_absolute_percentage_error(y_pred, y_vali)
print("mape: ",mape)
y_test = model.predict(test_data)
print(y_test)
print(y_test.shape)
result['num_sold'] = y_test
print(result)
result.to_csv('sample_submission_LR.csv',index=False)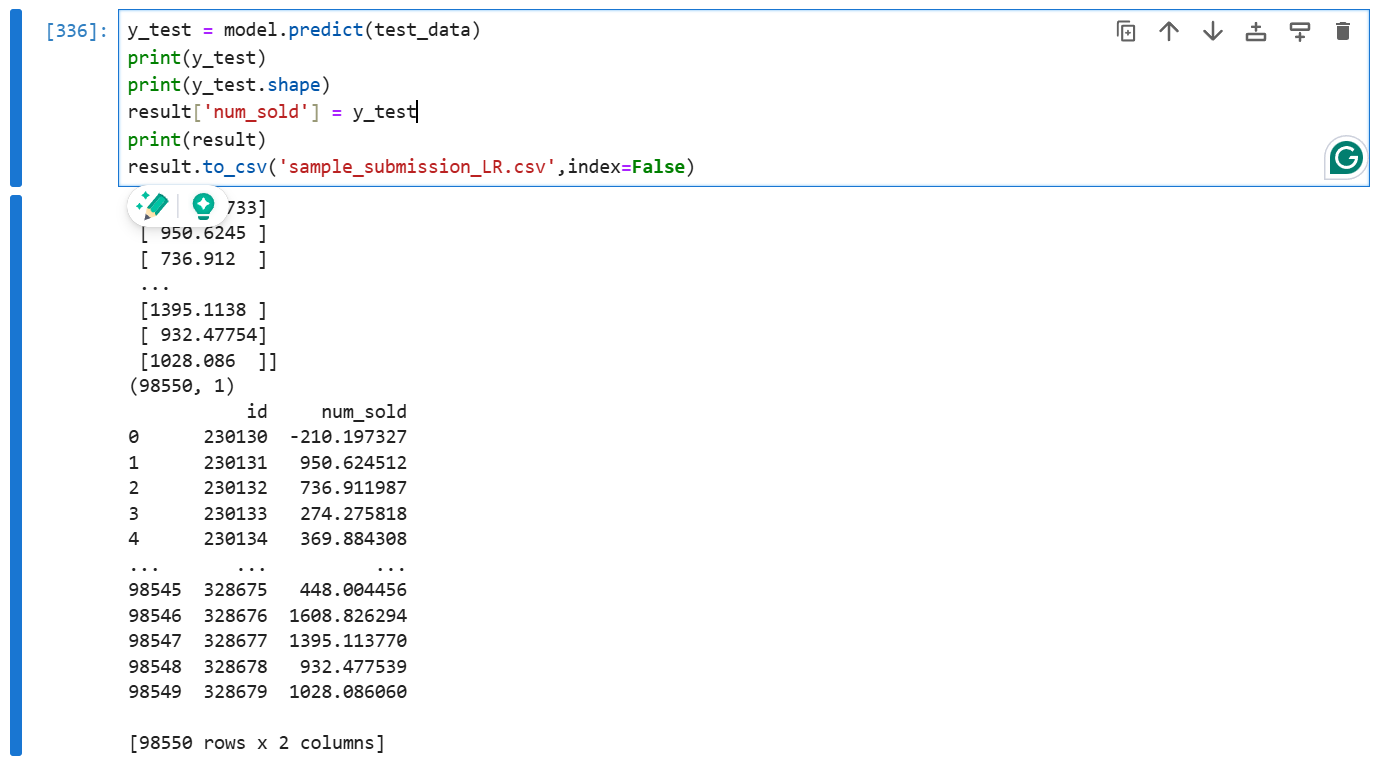
随机森林回归
from sklearn.ensemble import RandomForestRegressorX_train, X_vali, y_train, y_vali = train_test_split(train_data, train_labels, test_size = 0.2, random_state=42)
model = RandomForestRegressor()
model.fit(X_train, y_train)
y_pred = model.predict(X_vali)
mape = mean_absolute_percentage_error(y_pred, y_vali)
print("mape: ",mape)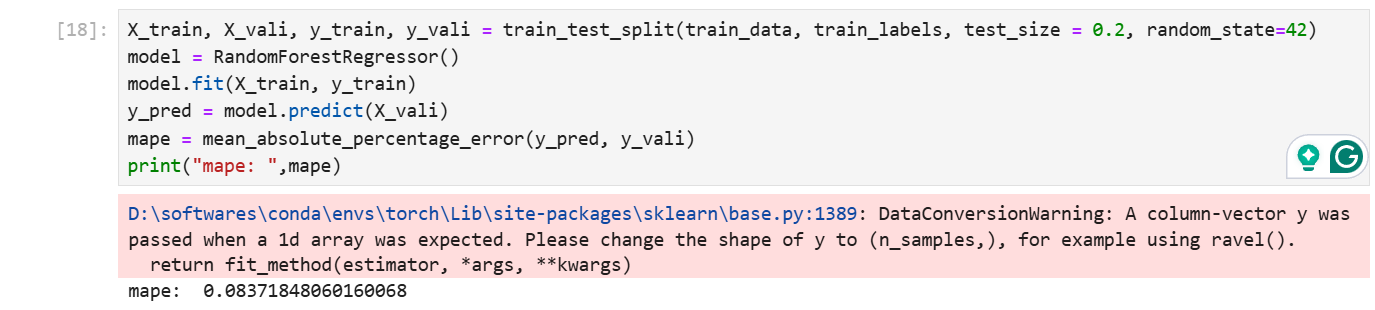
y_test = model.predict(test_data)
print(y_test)
print(y_test.shape)
result['num_sold'] = y_test
print(result)
result.to_csv('sample_submission_RFR.csv',index=False)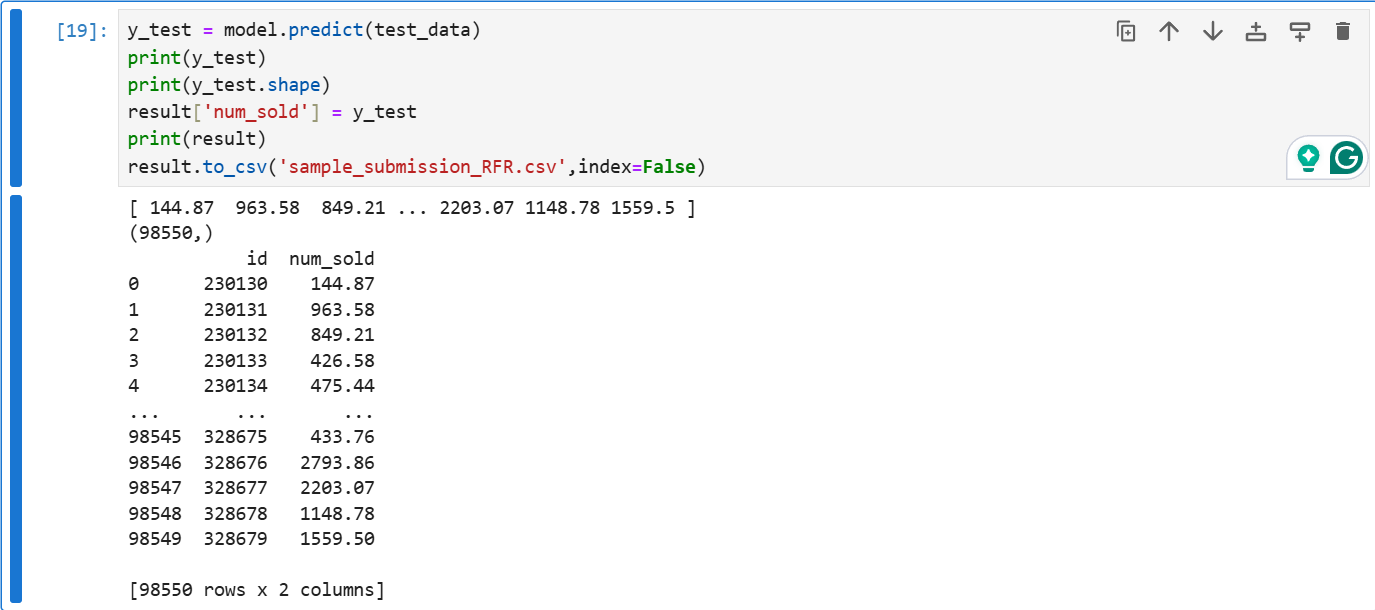
XGBoost
from xgboost import XGBRegressor X_train, X_vali, y_train, y_vali = train_test_split(train_data, train_labels, test_size = 0.2, random_state=42)
model = XGBRegressor(n_estimators = 200, #迭代次数
learning_rate = 0.1, #学习率
max_depth=20)
model.fit(X_train, y_train)
y_pred = model.predict(X_vali)
mape = mean_absolute_percentage_error(y_pred, y_vali)
print("mape: ",mape)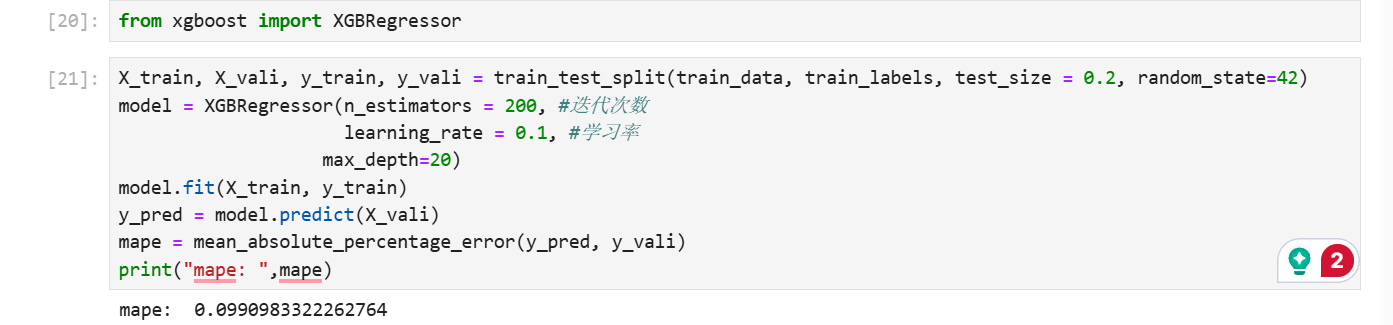
y_test = model.predict(test_data)
print(y_test)
print(y_test.shape)
result['num_sold'] = y_test
print(result)
result.to_csv('sample_submission_XGB.csv',index=False)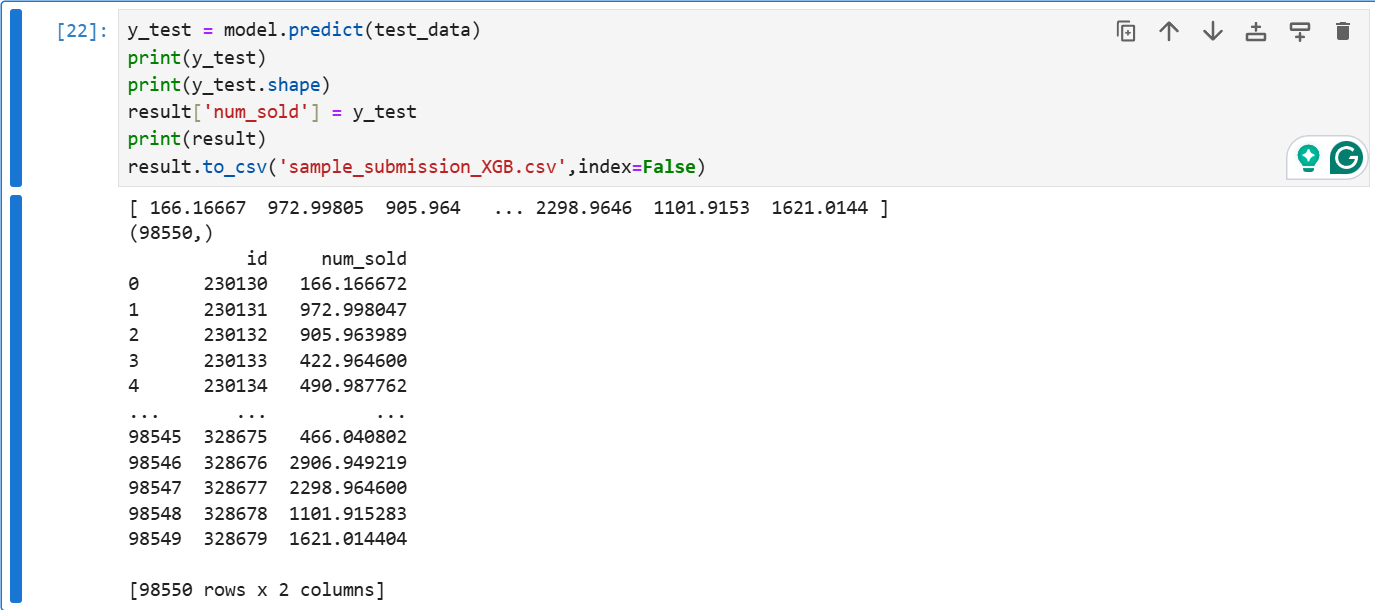
神经网络
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import TensorDataset, DataLoader
import numpy as np
from tqdm import tqdmdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")
X_train, X_vali, y_train, y_vali = train_test_split(train_data, train_labels, test_size = 0.2, random_state=42)
print(X_train.shape)
print(X_vali.shape)
print(y_train.shape)我们需要将数据集封装为dataset然后用DataLoader批量读入
# 将数据封装为 TensorDataset
dataset = TensorDataset(X_train, y_train)
# 创建 DataLoader
batch_size = 64
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
save_path = "./model.pth"以下是保存模型的简单代码
def save_model(model, optimizer, epoch, save_path):
checkpoint = {
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}
torch.save(checkpoint, save_path)
print(f"Saved model at {save_path}")以下是简单的两层Hidden Layer的神经网络
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(17, 64) # 输入层(17)-> 隐藏层(64)
self.fc2 = nn.Linear(64, 32) # 隐藏层(64)-> 隐藏层(64)
self.fc3 = nn.Linear(32, 1) # 隐藏层(64)-> 输出层(1)
def forward(self, x):
x = torch.relu(self.fc1(x)) # 激活函数
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
model = Net().to(device)
def mape(outputs, targets):
return torch.mean(torch.abs((outputs - targets) / targets))接下来开始我们的训练,注意由于是回归,准确率可以用自己确定的阈值来进行判断,即预测值与真实值小于阈值我们可以认为预测正确,当然这只是一个相对指标。
num_epochs = 60
optimizer = optim.Adam(model.parameters(), lr=0.005)
for epoch in range(num_epochs):
model.train()
total_loss = 0
total_mape = 0
correct = 0
with tqdm(dataloader, desc=f'Epoch {epoch+1}/{num_epochs}') as pbar:
for data, target in pbar:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = mape(output, target)
loss.backward()
optimizer.step()
total_loss += loss.item()
total_mape += mape(output, target).item()
# 计算准确率(这里我们简单地计算预测值与目标值最接近的比例)
pred = output.to('cpu').detach().numpy().flatten()
target = target.to('cpu').detach().numpy().flatten()
correct += np.sum(np.abs(pred - target) < 100)
pbar.set_postfix({
'loss': f'{loss.item():.4f}',
'mape': f'{total_mape/(len(dataloader)):.4f}',
'accuracy': f'{correct/(len(dataloader.dataset)):.2f}%'
})
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {total_loss/len(dataloader):.4f}, MAPE: {total_mape/len(dataloader):.4f}, Accuracy: {correct/len(dataloader.dataset):.2f}%')
if num_epochs % 20 == 0:
save_model(model, optimizer, num_epochs, save_path)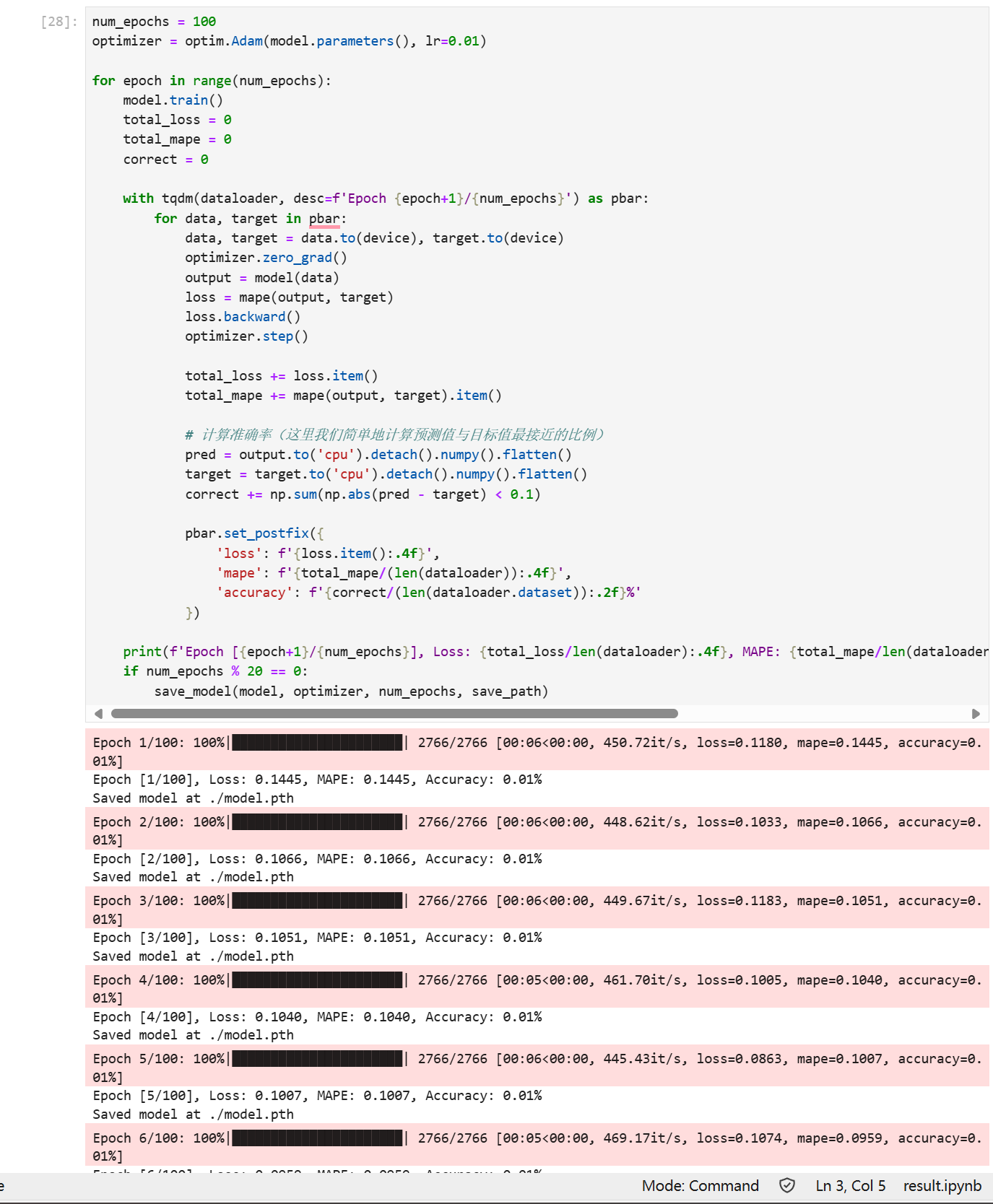
随后我们使用模型进行推理:
with torch.no_grad():
y_test = model(test_data.to(device))
print(y_test)
print(y_test.shape)
result['num_sold'] = y_test.to('cpu')
print(result)
result.to_csv('sample_submission_DNN.csv',index=False)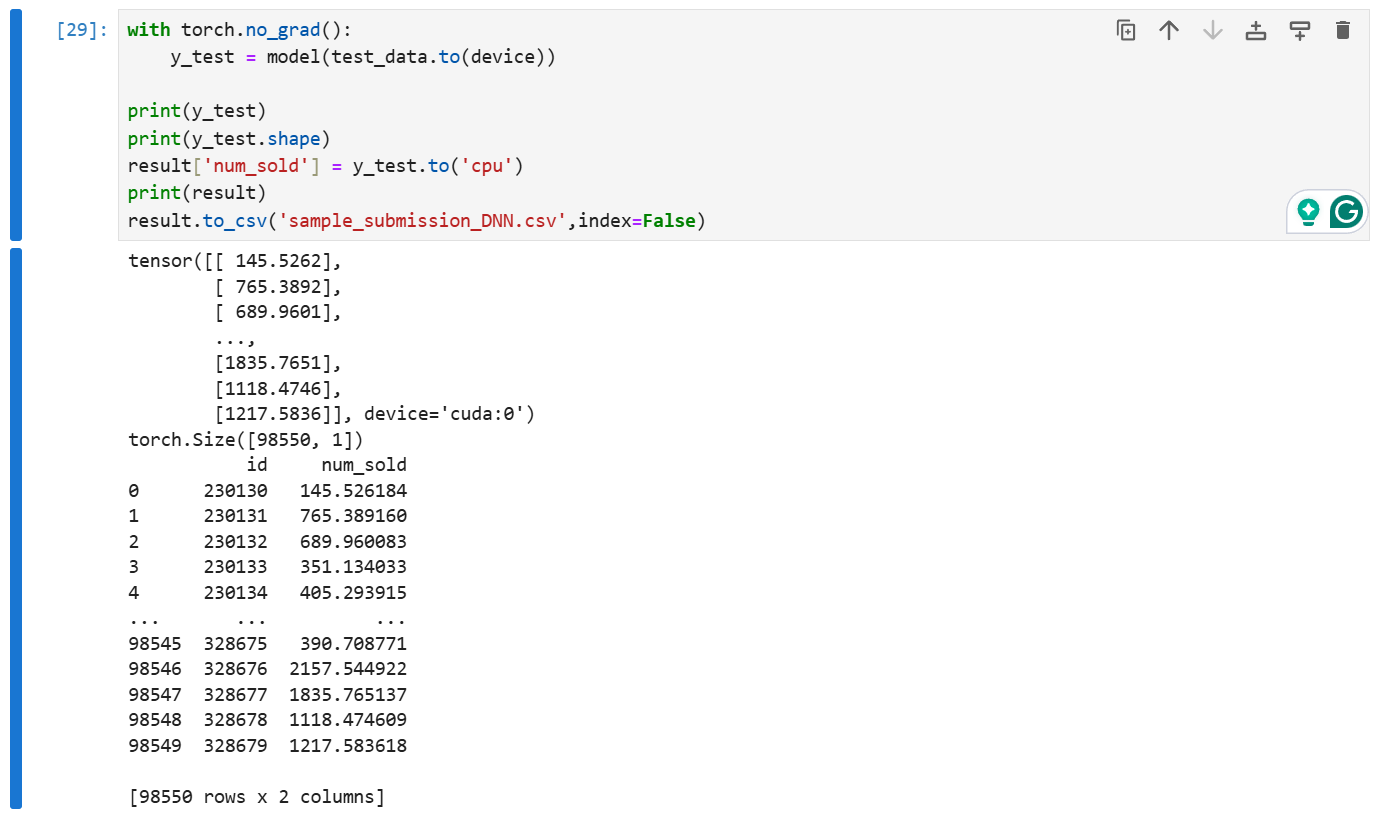
小结
这只是一个非常粗糙的模型,在数据的预处理部分我们没有主动去收集更多的数据,在kaggle其他人的结果中,我们可以看见加入了国家的GDP数据;另外我们其实忽略了时序特征;在模型方面,我们也没有做过多的调整,最终在比赛中排名1400/2100,后续可以对其他人的工作进行复现。
- 感谢你赐予我前进的力量
-
微信
- 支付宝